zephyr
大巫师
ABSTRACT
Corpus, especially parallel corpus, has become an indispensable instrument in many linguistic researches including translation studies and natural language processing studies. However, due to the limited sources of bilingual or multi-lingual materials, development of parallel corpora has lagged far behind other types of corpora.
In the meantime, with the appearance and prevalence of DVDs and Internet, films and television subtitles (captions), which are bi-lingual or multi-lingual by nature, are easier to get and the their volume, which is already huge, grows fast.
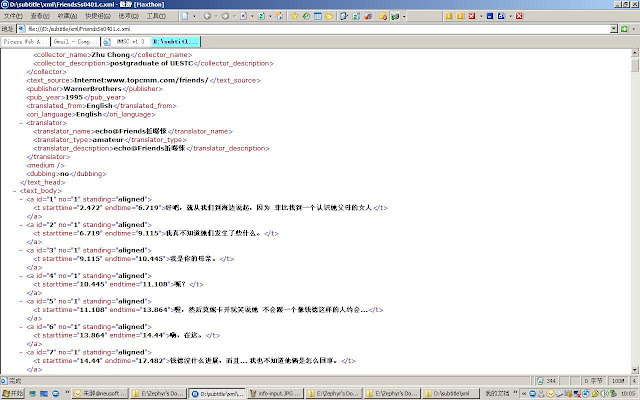
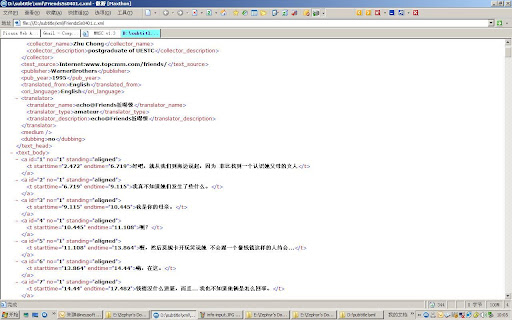
Therefore, the author makes an attempt to build a parallel corpus using the voluminous subtitles available on line or from DVDs, namely, the Mass Media Subtitle Corpus or MMSC in short. MMSC is designed to be open and extensible, with a framework that allows easy accesses as well as convenient management and maintaining. At the completion of the thesis, the MMSC contains no less than 1,500,000 words and 100,000 parallel units and is expected to receive much more texts from users and donators in due course.
The present paper centers on the creation of MMSC, after which several test studies conducted on it are introduced in an effort to discuss its possible usages in academic areas such as translation studies, translator training and English teaching, etc.
The creation of the MMSC contains several steps including overall design, subtitle selection and collection, text alignment, text annotation, concordance platform and maintenance interface design, etc. In the text alignment part, the author proposes a new aligning algorithm specially designed for subtitles, which is different from traditional algorithms that take statistical approaches.
The applications of the MMSC are exemplified at the end of the thesis through a few pilot studies.
In the end, potential usages of MMSC and one of its possible upgraded versions are suggested.
Keywords: corpus, film, television, subtitle, translation
Zhu Chong. Chengdu: UESTC, 2007
Corpus, especially parallel corpus, has become an indispensable instrument in many linguistic researches including translation studies and natural language processing studies. However, due to the limited sources of bilingual or multi-lingual materials, development of parallel corpora has lagged far behind other types of corpora.
In the meantime, with the appearance and prevalence of DVDs and Internet, films and television subtitles (captions), which are bi-lingual or multi-lingual by nature, are easier to get and the their volume, which is already huge, grows fast.
Therefore, the author makes an attempt to build a parallel corpus using the voluminous subtitles available on line or from DVDs, namely, the Mass Media Subtitle Corpus or MMSC in short. MMSC is designed to be open and extensible, with a framework that allows easy accesses as well as convenient management and maintaining. At the completion of the thesis, the MMSC contains no less than 1,500,000 words and 100,000 parallel units and is expected to receive much more texts from users and donators in due course.
The present paper centers on the creation of MMSC, after which several test studies conducted on it are introduced in an effort to discuss its possible usages in academic areas such as translation studies, translator training and English teaching, etc.
The creation of the MMSC contains several steps including overall design, subtitle selection and collection, text alignment, text annotation, concordance platform and maintenance interface design, etc. In the text alignment part, the author proposes a new aligning algorithm specially designed for subtitles, which is different from traditional algorithms that take statistical approaches.
The applications of the MMSC are exemplified at the end of the thesis through a few pilot studies.
In the end, potential usages of MMSC and one of its possible upgraded versions are suggested.
Keywords: corpus, film, television, subtitle, translation
Zhu Chong. Chengdu: UESTC, 2007
")