You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
一个关于KWIC编程的疑惑
- 主题发起人 ArthurW
- 时间

回复: 一个关于KWIC编程的疑惑
按照你的思路,假设字符串是aahaahaahaahaahaa,要查找的是aahaa,那岂不是要后退2个才行?
按照你的思路,假设字符串是aahaahaahaahaahaa,要查找的是aahaa,那岂不是要后退2个才行?
回复: 一个关于KWIC编程的疑惑
我的算法其实是这样:每次匹配之后把整个字符串的最左的1个字符去掉,在剩余部分继续匹配,如此反复,直到余下的不再包含key word
这个情况下我觉得也应该匹配5次,不知我的表达是不是清楚按照你的思路,假设字符串是aahaahaahaahaahaa,要查找的是aahaa,那岂不是要后退2个才行?
我的算法其实是这样:每次匹配之后把整个字符串的最左的1个字符去掉,在剩余部分继续匹配,如此反复,直到余下的不再包含key word
回复: 一个关于KWIC编程的疑惑
我个人觉得,应该是3个。
我个人觉得,应该是3个。
回复: 一个关于KWIC编程的疑惑
如果文本是I have a dream,检索的目标是由两个单词构成的词串,那么结果应该是几个呢?常规的正则表达式检索结果是2个,但我觉得应该是3个我个人觉得,应该是3个。
回复: 一个关于KWIC编程的疑惑
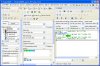
“I have a dream” 的2元组(2-Gram)确实应有3个。测试方法:把 “I have a dream” 保存到一个txt文件中,用正则表达式(\b\w+\b)(?=((\s+\b\w+\b){1}))在PowerGrep中的“Collect data”功能。具体操作如图:
如果文本是I have a dream,检索的目标是由两个单词构成的词串,那么结果应该是几个呢?常规的正则表达式检索结果是2个,但我觉得应该是3个
“I have a dream” 的2元组(2-Gram)确实应有3个。测试方法:把 “I have a dream” 保存到一个txt文件中,用正则表达式(\b\w+\b)(?=((\s+\b\w+\b){1}))在PowerGrep中的“Collect data”功能。具体操作如图: