You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
- 主题发起人 linp
- 时间
seanxpq
corpus explorer
回复: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
弄到词典的PDF版本,用OCR识别,存为TXT,再稍加编辑就可以了。
我的研究题目是要查一下在我的语料库里用了多少个英文片语.我想以牛津剑桥的英文片语字典做基础,将每个收录在这两大片语字典的片语都在我的语料库自动搜寻一下.请问各位我如何才能提取到收录在这两大英文片语字典的条目呢?是否有一个聪明的方法解决这个问题?我现在只能想到用人手每个片语输入电脑, 这可用上我几个月光阴啊!请各位高手帮忙!
弄到词典的PDF版本,用OCR识别,存为TXT,再稍加编辑就可以了。
Haiyang Ai
Administrator
回复: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
看有没有文本格式的片语录。使用 file-based concordance 可以批量搜索,不必一条一条手工做。
看有没有文本格式的片语录。使用 file-based concordance 可以批量搜索,不必一条一条手工做。
回覆: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
我找来了朗文及柯林斯短语字典(请看附加档案),朗文字典找来时已经有颇准确的OCR,但柯林斯字典是我自己买回来人手扫瞄的,扫描的质量不错,可惜没有很准确的OCR工具认字,试过了Acrobat Professional 9的OCR工具,效果不是很好.
请问各位能否帮忙解决两个问题:
1. 如何从已经过OCR处理的朗文字典提取我所需的短语列表?
2. 有没有准确的OCR软件可以介绍给我?
谢谢各位.
我找来了朗文及柯林斯短语字典(请看附加档案),朗文字典找来时已经有颇准确的OCR,但柯林斯字典是我自己买回来人手扫瞄的,扫描的质量不错,可惜没有很准确的OCR工具认字,试过了Acrobat Professional 9的OCR工具,效果不是很好.
请问各位能否帮忙解决两个问题:
1. 如何从已经过OCR处理的朗文字典提取我所需的短语列表?
2. 有没有准确的OCR软件可以介绍给我?
谢谢各位.
附件
xusun575
高级会员
回复: 回覆: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
看了你提供的材料,并亲手做了一下,是有"自动化一点的办法"的:熟悉正则,或熟悉word的高级查找替换,都能成功.
识别用的是abbyy9,效果非常好,好象没有比这更好的OCR工具了,你可以看一下OCR的结果.
思路就是要分析一下两种辞典的形式规律.
比如,longman的最大特点是其片语的字体和字号与其它描述部分有显著区别,这样,通过把该字体字号的找到,其它删除即可. 这个用word查找替换就可以了.
collins的特点是,大多数片语都在")"的后面,且后续的解释部分用"When..."或"If ...."开始的;如果是多重解释,且片语本身紧跟的是段落标记.这样也就很方便提取.collins用正则可能会更方便,但,word虽步骤多一点,只要习惯了,也很方便
附件的结果,都是用word做的,你可以参考一下.longman是finalised,而collins semifinal,这样你也思考一下.
使用提取过程中还有些细节,你可以边做边摸索.
OCR设置和语言选择也需要根据正率调试一下。如果这方面有困难,文件传给来,我给识别一下也非常简单。
谢谢指教!拿到文字档之後,文字档内会包含对每个片语的解释, 如果没有XML tags,是否真的要用人手将每一个片语的注解和它的Headword 分开呢?有没有自动化一点的方法?
看了你提供的材料,并亲手做了一下,是有"自动化一点的办法"的:熟悉正则,或熟悉word的高级查找替换,都能成功.
识别用的是abbyy9,效果非常好,好象没有比这更好的OCR工具了,你可以看一下OCR的结果.
思路就是要分析一下两种辞典的形式规律.
比如,longman的最大特点是其片语的字体和字号与其它描述部分有显著区别,这样,通过把该字体字号的找到,其它删除即可. 这个用word查找替换就可以了.
collins的特点是,大多数片语都在")"的后面,且后续的解释部分用"When..."或"If ...."开始的;如果是多重解释,且片语本身紧跟的是段落标记.这样也就很方便提取.collins用正则可能会更方便,但,word虽步骤多一点,只要习惯了,也很方便
附件的结果,都是用word做的,你可以参考一下.longman是finalised,而collins semifinal,这样你也思考一下.
使用提取过程中还有些细节,你可以边做边摸索.
OCR设置和语言选择也需要根据正率调试一下。如果这方面有困难,文件传给来,我给识别一下也非常简单。
附件
Last edited:
seanxpq
corpus explorer
回复: 回覆: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
能否麻烦孙教授把WORD中查询替换的具体过程讲讲?谢谢!
看了你提供的材料,并亲手做了一下,是有"自动化一点的办法"的:熟悉正则,或熟悉word的高级查找替换,都能成功.
识别用的是abbyy9,效果非常好,好象没有比这更好的OCR工具了,你可以看一下OCR的结果.
思路就是要分析一下两种辞典的形式规律.
比如,longman的最大特点是其片语的字体和字号与其它描述部分有显著区别,这样,通过把该字体字号的找到,其它删除即可. 这个用word查找替换就可以了.
collins的特点是,大多数片语都在")"的后面,且后续的解释部分用"When..."或"If ...."开始的;如果是多重解释,且片语本身紧跟的是段落标记.这样也就很方便提取.collins用正则可能会更方便,但,word虽步骤多一点,只要习惯了,也很方便
附件的结果,都是用word做的,你可以参考一下.longman是finalised,而collins semifinal,这样你也思考一下.
使用提取过程中还有些细节,你可以边做边摸索.
OCR设置和语言选择也需要根据正率调试一下。如果这方面有困难,文件传给来,我给识别一下也非常简单。
能否麻烦孙教授把WORD中查询替换的具体过程讲讲?谢谢!
xusun575
高级会员
回复: 回覆: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
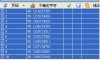
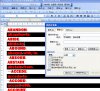
以longman为例:
字体是Franklin Gothic Heavy,字号为10
前三步见附图.
最后一步是存为txt除噪,导入word删除其它符号、排序整理即可。
能否麻烦孙教授把WORD中查询替换的具体过程讲讲?谢谢!
以longman为例:
字体是Franklin Gothic Heavy,字号为10
前三步见附图.
最后一步是存为txt除噪,导入word删除其它符号、排序整理即可。
附件
xusun575
高级会员
回复: 回覆: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
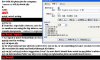
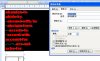
前三步是:
1、把Franklin Gothic Heavy,字号为10的字符加红(并可加粗);
2、非红字符删除;
3、第三步删除全部大写字母(使用通配符)。
以longman为例:
字体是前三步见附图.
最后一步是存为txt除噪,导入word删除其它符号、排序整理即可。
前三步是:
1、把Franklin Gothic Heavy,字号为10的字符加红(并可加粗);
2、非红字符删除;
3、第三步删除全部大写字母(使用通配符)。
回覆: 回复: 回覆: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
老师,很感谢您详尽的解释。我试用过您介绍的Abbyy软件了,的确非常准确。可惜我还是不会调试该系统,未知可否麻烦您帮忙一下OCR两本字典,此後我会根据老师的提示自己尝试提取短语项目。谢谢你。
柯林斯字典(200MB, 希望连结能用)
http://dl.dropbox.com/u/32136110/Collins COBUILD Phrasal Verbs Dictionary.pdf
朗文字典(200MB, 希望连结能用)
http://dl.dropbox.com/u/32136110/Longman phrasal verbs dictionary.pdf
看了你提供的材料,并亲手做了一下,是有"自动化一点的办法"的:熟悉正则,或熟悉word的高级查找替换,都能成功.
识别用的是abbyy9,效果非常好,好象没有比这更好的OCR工具了,你可以看一下OCR的结果.
思路就是要分析一下两种辞典的形式规律.
比如,longman的最大特点是其片语的字体和字号与其它描述部分有显著区别,这样,通过把该字体字号的找到,其它删除即可. 这个用word查找替换就可以了.
collins的特点是,大多数片语都在")"的后面,且后续的解释部分用"When..."或"If ...."开始的;如果是多重解释,且片语本身紧跟的是段落标记.这样也就很方便提取.collins用正则可能会更方便,但,word虽步骤多一点,只要习惯了,也很方便
附件的结果,都是用word做的,你可以参考一下.longman是finalised,而collins semifinal,这样你也思考一下.
使用提取过程中还有些细节,你可以边做边摸索.
OCR设置和语言选择也需要根据正率调试一下。如果这方面有困难,文件传给来,我给识别一下也非常简单。
老师,很感谢您详尽的解释。我试用过您介绍的Abbyy软件了,的确非常准确。可惜我还是不会调试该系统,未知可否麻烦您帮忙一下OCR两本字典,此後我会根据老师的提示自己尝试提取短语项目。谢谢你。
柯林斯字典(200MB, 希望连结能用)
http://dl.dropbox.com/u/32136110/Collins COBUILD Phrasal Verbs Dictionary.pdf
朗文字典(200MB, 希望连结能用)
http://dl.dropbox.com/u/32136110/Longman phrasal verbs dictionary.pdf
xusun575
高级会员
回复: 回覆: 回复: 回覆: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
好的,晚上我给你处理一下,整个过程需要一点时间,办公室弄一下,人歇PC不歇,但愿能下载啊.
老师,很感谢您详尽的解释。我试用过您介绍的Abbyy软件了,的确非常准确。可惜我还是不会调试该系统,未知可否麻烦您帮忙一下OCR两本字典,此後我会根据老师的提示自己尝试提取短语项目。谢谢你。
柯林斯字典(200MB, 希望连结能用)
http://dl.dropbox.com/u/32136110/Collins COBUILD Phrasal Verbs Dictionary.pdf
朗文字典(200MB, 希望连结能用)
http://dl.dropbox.com/u/32136110/Longman phrasal verbs dictionary.pdf
好的,晚上我给你处理一下,整个过程需要一点时间,办公室弄一下,人歇PC不歇,但愿能下载啊.
回覆: 回复: 回覆: 回复: 回覆: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
非常感激老师的帮忙!
好的,晚上我给你处理一下,整个过程需要一点时间,办公室弄一下,人歇PC不歇,但愿能下载啊.
非常感激老师的帮忙!
回覆: 回复: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
谢谢老师在百忙中仍抽空帮忙,我会现在先开始处理朗文字典,然後再处理柯林斯字典,遇到问题或完成後再发帖跟大家分享成果.
好了. 两部辞典你都试着整理一下.
先Longman后Collins, 有了心得或问题,可在这个帖子下交流,让大家分享解决.
谢谢老师在百忙中仍抽空帮忙,我会现在先开始处理朗文字典,然後再处理柯林斯字典,遇到问题或完成後再发帖跟大家分享成果.
回覆: 回复: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
谢谢您介绍新软件PowerGREP.我正在处理朗文字典,而且都有用上Regex.我找到了朗文字典变化出五千短语的动词(因为它们都是大写的),可是这距离目标还差很远.总是觉得有部分有用的资料在自动化的过程中不慎被去掉,到时可能又要用人手对一次才能确保资料准确.
可以考虑用powergrep运用正则表达式提取。
由于本人正则表达式也是刚刚入门,所以用了个简单的正则表达式把collins词典中的大部分片语提取出来(附件 collins.txt).
谢谢您介绍新软件PowerGREP.我正在处理朗文字典,而且都有用上Regex.我找到了朗文字典变化出五千短语的动词(因为它们都是大写的),可是这距离目标还差很远.总是觉得有部分有用的资料在自动化的过程中不慎被去掉,到时可能又要用人手对一次才能确保资料准确.
xusun575
高级会员
回复: 回覆: 回复: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
看你这段描述,你在提取时肯定出现了问题.
处理中的细节要注意和调整.pdf的量对识别结果是有影响的.
首先,如果你使用的是我提供的OCR稿,longman的短语动词肯定不会大写.
第二, "自动化的过程",如果是指OCR,那么肯定不会"去掉"任何内容.情况可能是有些未被识别成文字,而是作为图表(图形)保存在OCR结果文件中.
为此,建议你首先查找出这些图形部分,并逐一将其替换出相应的短语动词,(很方便,在word中有 ^g查找即可).
然后再分析文本, 以便提取所有的短语动词.
谢谢您介绍新软件PowerGREP.我正在处理朗文字典,而且都有用上Regex.我找到了朗文字典变化出五千短语的动词(因为它们都是大写的),可是这距离目标还差很远.总是觉得有部分有用的资料在自动化的过程中不慎被去掉,到时可能又要用人手对一次才能确保资料准确.
谢谢您介绍新软件PowerGREP.我正在处理朗文字典,而且都有用上Regex.我找到了朗文字典变化出五千短语的动词(因为它们都是大写的),可是这距离目标还差很远.总是觉得有部分有用的资料在自动化的过程中不慎被去掉,到时可能又要用人手对一次才能确保资料准确.
看你这段描述,你在提取时肯定出现了问题.
处理中的细节要注意和调整.pdf的量对识别结果是有影响的.
首先,如果你使用的是我提供的OCR稿,longman的短语动词肯定不会大写.
第二, "自动化的过程",如果是指OCR,那么肯定不会"去掉"任何内容.情况可能是有些未被识别成文字,而是作为图表(图形)保存在OCR结果文件中.
为此,建议你首先查找出这些图形部分,并逐一将其替换出相应的短语动词,(很方便,在word中有 ^g查找即可).
然后再分析文本, 以便提取所有的短语动词.
xusun575
高级会员
回复: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
学有所成可喜可贺
可以考虑用powergrep运用正则表达式提取。
由于本人正则表达式也是刚刚入门,所以用了个简单的正则表达式把collins词典中的大部分片语提取出来(附件 collins.txt).
学有所成可喜可贺
回复: 如何可以简单地提取牛津剑桥的英文片语字典内收录的片语?
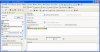
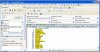
谢谢孙教授美言。这几天孩子比较闹腾,也只好利用她睡觉的时间来动手搞搞正则表达式。To linp:对于collins词典,我又把原来的提取表达式改了一下,这样就可以一次性提取大部分分布有规则的片语。不过提取之前最好把文本稍微整理干净,要不然可能会出现遗漏。请查看附件,也许能帮点忙。
PowerGrep里用此表达式(见附件:正则表达式collins)
提取出来后纯净文本,可选用editpro软件的查找替换(见附件:去噪)
提取出来的片语见 txt附件。大约有3000个。如有遗漏可能在文本扫描或纯净方面还有问题。
谢谢孙教授美言。这几天孩子比较闹腾,也只好利用她睡觉的时间来动手搞搞正则表达式。To linp:对于collins词典,我又把原来的提取表达式改了一下,这样就可以一次性提取大部分分布有规则的片语。不过提取之前最好把文本稍微整理干净,要不然可能会出现遗漏。请查看附件,也许能帮点忙。
PowerGrep里用此表达式(见附件:正则表达式collins)
提取出来后纯净文本,可选用editpro软件的查找替换(见附件:去噪)
提取出来的片语见 txt附件。大约有3000个。如有遗漏可能在文本扫描或纯净方面还有问题。