各位老师好,作为初学者,我纠结了很久,终于鼓起勇气将自己的问题贴出来,希望得到老师们的帮助和指点。
研究英语报章(语料来源主要是China Daily,我已经收集了China Daily2011年7、8、9三个月的文本,分为6个主题,一共972,796 tokens和26,955 types)的高频动词。之前我理解的高频动词就是China daily中按词频由大及小排列最靠前的前五十个,或者前二十个。现在我想定义为与COCA的新闻语料库中动词词表相比,出现频率异常高,或者相比较而言过度使用的动词。我现在的第一步是要将这些动词找出来。自建的微型语料库定义为MCCD。
我的方法如下:
1. 产生MCCD的动词词表。
2. 从网上(http://www.wordfrequency.info/)下载了Word lists + genre frequency,筛选出新闻类别的动词词表,截图见附件coca.jpg。
3. 生成主题词表。(观察文本是MCCD生文本,因为没有COCA新闻语料,我在AntConc的tool preferences中的reference corpus options中选择第二个项use word list)。
我的问题如下:
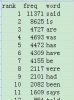
对于步骤1:利用MCCD生文本得到wordlist(使用了stoplist词表),在excel中人工筛选出动词词表a,截图见附件mccd_a,也可以打开赋码后的文本,利用Cluster选项卡(从该论坛看到的),得到动词词表b,截图见附件mccd_b。问题是:我该使用哪一个呢?词表b如何得到原形词构成的词表?
对于步骤2:网上下载的新闻类词表为什么没有期望的say,report等词呢?
对于步骤3:通过生成主题词表的方法来得到China Daily中频率异常高的词可行吗?感觉不靠谱,想用书上(《语料库应用教程》P94)的Chi-Square Calculator,直接挑选出最后一列标记为+号的动词,可是最左边一列的动词选用哪个呢?它们在COCA新闻语料(相当于corpus 2)中的频率怎么得到呢?
将问题写完,我有点晕了,希望各位老师在有空的时候能够指点迷津。非常感谢!
研究英语报章(语料来源主要是China Daily,我已经收集了China Daily2011年7、8、9三个月的文本,分为6个主题,一共972,796 tokens和26,955 types)的高频动词。之前我理解的高频动词就是China daily中按词频由大及小排列最靠前的前五十个,或者前二十个。现在我想定义为与COCA的新闻语料库中动词词表相比,出现频率异常高,或者相比较而言过度使用的动词。我现在的第一步是要将这些动词找出来。自建的微型语料库定义为MCCD。
我的方法如下:
1. 产生MCCD的动词词表。
2. 从网上(http://www.wordfrequency.info/)下载了Word lists + genre frequency,筛选出新闻类别的动词词表,截图见附件coca.jpg。
3. 生成主题词表。(观察文本是MCCD生文本,因为没有COCA新闻语料,我在AntConc的tool preferences中的reference corpus options中选择第二个项use word list)。
我的问题如下:
对于步骤1:利用MCCD生文本得到wordlist(使用了stoplist词表),在excel中人工筛选出动词词表a,截图见附件mccd_a,也可以打开赋码后的文本,利用Cluster选项卡(从该论坛看到的),得到动词词表b,截图见附件mccd_b。问题是:我该使用哪一个呢?词表b如何得到原形词构成的词表?
对于步骤2:网上下载的新闻类词表为什么没有期望的say,report等词呢?
对于步骤3:通过生成主题词表的方法来得到China Daily中频率异常高的词可行吗?感觉不靠谱,想用书上(《语料库应用教程》P94)的Chi-Square Calculator,直接挑选出最后一列标记为+号的动词,可是最左边一列的动词选用哪个呢?它们在COCA新闻语料(相当于corpus 2)中的频率怎么得到呢?
将问题写完,我有点晕了,希望各位老师在有空的时候能够指点迷津。非常感谢!

")