自己在尝试做一个科技文献语料库,目的是研究其文体特征,设计的是保存语料全文本,在转换格式过程中,发现有很多格式TXT无法读取,比如在科技论文中经常出现一些公式,符号,图表等(如图),那么该怎么整理类似的文本?怎么去赋码?还有就是标记引用文献出处的数字是不是要去掉?“保存全文本”指的是通篇所有包括author, title, abstract, ket words, body, acknowledgement, claims, references and tables and figures, 还是根据研究目的自己选择?
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
求教:关于文本整理的一些细节问题
- 主题发起人 xiudaya
- 时间
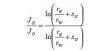

回复: 求教:关于文本整理的一些细节问题
The common practice is either you delete the tables and/or figures, and put <figure><table> there instead, or you delete them for good, if you only wish to study the linguistic forms of the text in the future.
Don't what you mean, or what you were asked do, by “保存全文本”.
One thing to share with you, data collection, more often than not, is research purpose driven.
The common practice is either you delete the tables and/or figures, and put <figure><table> there instead, or you delete them for good, if you only wish to study the linguistic forms of the text in the future.
Don't what you mean, or what you were asked do, by “保存全文本”.
One thing to share with you, data collection, more often than not, is research purpose driven.
回复: 求教:关于文本整理的一些细节问题
According to Sinclair (1991: 19), there are at least five reasons to use whole documents: (1) There is no worry about the marked differences that have been noted between different parts of a text. (2) A corpus made up of whole documents is open to a wider range of linguistic studies than a collection of short samples. (3) There is no worry about the validity of the sampling techniques. (4) Smaller, more specialized corpora can be drawn from a large corpus. (5) Collocation requires very large corpora to secure sufficient evidence for statistical treatment. this paragraph is abstracted from a paper, and i aslo have also read the bool by sinclair. But I am still not clear about the ''whole' text. dose that mean all of the information of text? including reference and acknolegement and some claims, which have nothing to do with the study, i think.
secondly, some words appear differently in text such as carbon dioxide in CO2, and there are also some wrong formula such as Kv =- (Q-Q0) (V-V0) that the v and 0 should be much smaller than the letters beside. then, how to deal with these probelms?
thanks a lot! and i want to say,using corpora: a practical coursebook is really so helpfull for me. thank all of you again!The common practice is either you delete the tables and/or figures, and put <figure><table> there instead, or you delete them for good, if you only wish to study the linguistic forms of the text in the future.
Don't what you mean, or what you were asked do, by “保存全文本”.
One thing to share with you, data collection, more often than not, is research purpose driven.
According to Sinclair (1991: 19), there are at least five reasons to use whole documents: (1) There is no worry about the marked differences that have been noted between different parts of a text. (2) A corpus made up of whole documents is open to a wider range of linguistic studies than a collection of short samples. (3) There is no worry about the validity of the sampling techniques. (4) Smaller, more specialized corpora can be drawn from a large corpus. (5) Collocation requires very large corpora to secure sufficient evidence for statistical treatment. this paragraph is abstracted from a paper, and i aslo have also read the bool by sinclair. But I am still not clear about the ''whole' text. dose that mean all of the information of text? including reference and acknolegement and some claims, which have nothing to do with the study, i think.
secondly, some words appear differently in text such as carbon dioxide in CO2, and there are also some wrong formula such as Kv =- (Q-Q0) (V-V0) that the v and 0 should be much smaller than the letters beside. then, how to deal with these probelms?
回复: 求教:关于文本整理的一些细节问题
Don't buy authorities' ideas word by word. Authorities make mistakes too, and often times, their arguments only make sense from a certain perpsective of observing language, which might not be shared by other scholars. To put it differently John Sinclair might be wrong or right, depending on whether you hold your own or share his philosophy of language.
In your case, you can have your own decisions regarding how to treat variants of the same term, such as carbon dioxide and CO2, and also other types of technical formulae, and stuff like that. The overruling principle is to keep consistent throughout your corpus.
Don't buy authorities' ideas word by word. Authorities make mistakes too, and often times, their arguments only make sense from a certain perpsective of observing language, which might not be shared by other scholars. To put it differently John Sinclair might be wrong or right, depending on whether you hold your own or share his philosophy of language.
In your case, you can have your own decisions regarding how to treat variants of the same term, such as carbon dioxide and CO2, and also other types of technical formulae, and stuff like that. The overruling principle is to keep consistent throughout your corpus.