如题,我利用antconc共统计出自建语料库中含有形容词125399条,但是其中包括了同一词语重复出现的数目,所以怎样利用antconc查出含有多少个不同的形容词??急求解答,谢谢了
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
如何使用antconc统计出形容词词条数
- 主题发起人 lijingyan0921
- 时间
回复: 如何使用antconc统计出形容词词条数
我是自建的中文语料库,是用ictclas的北大二级标准分词标注的。你的语料格式是什么?如果是CLAWS或Tree Tagger标注过的,你可以试试附件中的perl脚本文件,解压后双击即可运行。运行前请安装 Perl解释器。
回复: 如何使用antconc统计出形容词词条数
就是这样,因为如果输入/NS只能统计出此词类所有词语出现的词数,而不能统计出不重复的词条数。不介意的话贴一段语料上来看看。
附件

回复: 如何使用antconc统计出形容词词条数
我下载了您提供的软件,然后按提示进行运行,结果没有出现查询的txt文本解压后双击即可运行,按要求输入后可获得词表文件。运行前请安装 Perl 解释器
回复: 如何使用antconc统计出形容词词条数
谢谢你...我喜欢这个论坛非常多,因为它是非常丰富的...
谢谢你...我喜欢这个论坛非常多,因为它是非常丰富的...
回复: 如何使用antconc统计出形容词词条数
把查出来的频表复制到EXCEL里再分析。。。
把查出来的频表复制到EXCEL里再分析。。。
回复: 如何使用antconc统计出形容词词条数
标注好的语料用PowerConc来分析,得到各个词性的数目非常简单。http://ishare.iask.sina.com.cn/f/35649470.html
比如,下图显示,adj,形容词共出现1788次,点击数字1788会回到原文的concordance lines。
标注好的语料用PowerConc来分析,得到各个词性的数目非常简单。http://ishare.iask.sina.com.cn/f/35649470.html
比如,下图显示,adj,形容词共出现1788次,点击数字1788会回到原文的concordance lines。
附件
回复: 如何使用antconc统计出形容词词条数
I have started learning the Chinese corpus as a part of my studies. Even though the topic sounds interesting, it is very difficult to understand the whole idea and figure out the problems. The antconc statistics is the tough part for me.
__________________
Chris
snoring remedies
I have started learning the Chinese corpus as a part of my studies. Even though the topic sounds interesting, it is very difficult to understand the whole idea and figure out the problems. The antconc statistics is the tough part for me.
__________________
Chris
snoring remedies
回复: 如何使用antconc统计出形容词词条数
谢谢许老师,我正好也遇到这样的问题,太感谢了。
如果是中文语料,请将语料文本中的/替换成下划线_。即:中国/n变成中国_n。
然后操作更简单,可以软件目录下Sample_texts的ZH_LCMC_SEG_POS_ANSI_samples的语料测试
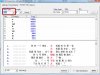
不用做设置,在N-gram list窗口,data type改为POS就可以了。其中的a(形容词)有960次,点击960,会出现concordance lines。
见下图
谢谢许老师,我正好也遇到这样的问题,太感谢了。