You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
用Wordsimith4检索CLEC的子集st3发现数据有问题?请指教。
- 主题发起人 corpora
- 时间
回复: 用Wordsimith4检索CLEC的子集st3发现数据有问题?请指教。
这个数字应当是出去其中方括号中的错误代码之后的实际字数。
另外我从桂诗春关于clec的介绍里写的是st3的库容为209043
这个数字应当是出去其中方括号中的错误代码之后的实际字数。
回复: 用Wordsimith4检索CLEC的子集st3发现数据有问题?请指教。
许博士说得有道理,你在stoplist 加上方括号和所有错误代码试试看,我的统计里没有加
许博士说得有道理,你在stoplist 加上方括号和所有错误代码试试看,我的统计里没有加
回复: 用Wordsimith4检索CLEC的子集st3发现数据有问题?请指教。
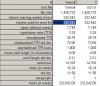
感谢各位的帮助,获益匪浅。但是hittle2008, 奇怪的是,我试了很多次,我检索到的结果的tokens (running words ) in text ;和token used for wordlist 数值都有很大差异,(无论设置stoplist和不设置stoplist情况下)
另外,我在sopplist里设了比如the这个单词,检索的结果,只是frequency列表里,没有了the的频次,而总的statistics的信息和不设sopplist的信息完全一样。即统计结果完全一样,这是怎么回事啊??!!
感谢各位的帮助,获益匪浅。但是hittle2008, 奇怪的是,我试了很多次,我检索到的结果的tokens (running words ) in text ;和token used for wordlist 数值都有很大差异,(无论设置stoplist和不设置stoplist情况下)
另外,我在sopplist里设了比如the这个单词,检索的结果,只是frequency列表里,没有了the的频次,而总的statistics的信息和不设sopplist的信息完全一样。即统计结果完全一样,这是怎么回事啊??!!
Last edited:
回复: 用Wordsimith4检索CLEC的子集st3发现数据有问题?请指教。
应该是你的设置有问题
应该是你的设置有问题
Re: 回复: 用Wordsimith4检索CLEC的子集st3发现数据有问题?请指教。
谢谢,还有些发现:
WST4中的tokens in text 统计标点,但把连续标点算作一个,数字也一样;而tokens used for word list 不统计标点,也把连续数字算做一个。
试统计 200..5,
tokens in text 是4个(200/../5/,)
tokens used for word list 是2个 (200/5)
望指正
All numerals are collapsed into the category # in the wordsmith wordlist, though they are counted as running words in the text.
谢谢,还有些发现:
WST4中的tokens in text 统计标点,但把连续标点算作一个,数字也一样;而tokens used for word list 不统计标点,也把连续数字算做一个。
试统计 200..5,
tokens in text 是4个(200/../5/,)
tokens used for word list 是2个 (200/5)
望指正
回复: 用Wordsimith4检索CLEC的子集st3发现数据有问题?请指教。
奇怪,为什么我的两个数字都一样呢,均为2
奇怪,为什么我的两个数字都一样呢,均为2
回复: 用Wordsimith4检索CLEC的子集st3发现数据有问题?请指教。
This happens only in the case when you don't check the box "numbers in wordlist" under the settings of "Languages".Once checked, it would make each number in the text counted as a specific token, and the number of "tokens (running word) in text" is in most cases equal to that of "tokens used for wordlist".
All numerals are collapsed into the category # in the wordsmith wordlist, though they are counted as running words in the text.
This happens only in the case when you don't check the box "numbers in wordlist" under the settings of "Languages".Once checked, it would make each number in the text counted as a specific token, and the number of "tokens (running word) in text" is in most cases equal to that of "tokens used for wordlist".