You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
如果写正则表达式
- 主题发起人 armstrong
- 时间
李亮1975重庆
语料库快乐军政委
对应的VBS脚本,VBS脚本转换而成的EXE,及其源代码
假设你的文件都是在同一个文件夹且都是txt的文件扩展名,并且看起来你的替换规则是“把每个文件的第一行的等于号之前的字符串抓出来,等于符号本身删除掉,在后续的每个汉语词之后加上/n/以及刚才的等于符号之前的那个字符串且再接上一个空格”,为了安全起见就针对每个文件而生成一个相同文件名称的.log文件,而.log文件都是双击被“记事本”打开的。
附件中的“小程序vbs.vbs”,把它放到跟其他的txt文件在同一个文件夹,双击运行它,它提示你“本文件夹处理完毕!所有的.txt文件都生成了对应的.log文件了”,就算是成功运行了。如果你的txt分布在不同的文件夹,你就继续把这个脚本拷贝到其他的文件夹去运行或者让其他的txt到脚本所在的文件夹来。如果你是Windows XP的话,就直接成功了。而你如果是Windows Vista或Windows 7的话,它们都往往不能直接运行VBS(VBscript)脚本的,所以,我用“vbs转exe程序”把我写的vbs脚本也变成了一个标准的exe,是独立运行了,而不需要借助system32文件夹中的wscript.exe或cscript.exe来运行了。你的win7或Vista不能运行我的vbs脚本的话就用vbs转换的exe吧,双击就运行了。【备注:对着vbs文件,点右键,选择“编辑”或“打开方式”为“记事本”,就能查看vbs的源代码了】
下载“vbs转exe程序”,是在
http://ishare.iask.sina.com.cn/f/6503634.html?from=like
整个vbs的完整代码如下……
-------------------------
Set fso1 = CreateObject("scripting.filesystemobject")
For Each file1 In fso1.GetFolder(".").Files
If Right(file1.Name, 4) = ".txt" Then
Set old_file = fso1.OpenTextFile(Left(file1.Name, Len(file1.Name) - 4) & ".txt")
Set new_file = fso1.CreateTextFile(Left(file1.Name, Len(file1.Name) - 4) & ".log")
the_line = old_file.ReadLine
border_position = InStr(1, the_line, "=")
new_tail = "/n/" & Left(the_line, border_position - 1) & " "
new_file.WriteLine (Replace(Trim(Right(the_line, Len(the_line) - border_position)) & " ", " ", new_tail))
old_file.Close
new_file.Close
Set old_file = Nothing
Set new_file = Nothing
End If
Next
MsgBox "本文件夹处理完毕!所有的.txt文件都生成了对应的.log文件了"
------------------
vbs是vbscript的缩写,是微软公司的专利技术,用来进行网站后台或网页前端的编程,也可以用来进行各种Windows的自动化管理,包括对文本文件或大型XML语料库的任意操作(增删查改)。“*.vbs”文件的运行,总是依赖c:\windows\system32\wscript.exe或cscript.exe。如果杀毒软件禁止了或你删除了这两个exe的话,vbs脚本就无法运行了,不过,通常不会出现这种情况的。其实,vbs编程蕴藏着正则表达式和数据库访问和互联网通信的全面功能,也能轻松编写出“抓取网页语料而自动保存到本地的智能化爬虫”呢,所以,优盘上呀,移动硬盘呀,往往变成了vbs编写的病毒的泛滥之地。VBS的语法就是BASIC,是微软血脉的BASIC版本的网页版兼本地版,而VBA则是微软血脉的BASIC版本的“Office嵌入版(必须依赖且运行于Office软件)”。从功能强弱与学习难度的角度,我们可以把VB叫做“大哥”,VBS叫做“二哥”,VBA叫做“三哥”,对了,“VB.NET”就是“大哥大”了,嘻嘻
假设你的文件都是在同一个文件夹且都是txt的文件扩展名,并且看起来你的替换规则是“把每个文件的第一行的等于号之前的字符串抓出来,等于符号本身删除掉,在后续的每个汉语词之后加上/n/以及刚才的等于符号之前的那个字符串且再接上一个空格”,为了安全起见就针对每个文件而生成一个相同文件名称的.log文件,而.log文件都是双击被“记事本”打开的。
附件中的“小程序vbs.vbs”,把它放到跟其他的txt文件在同一个文件夹,双击运行它,它提示你“本文件夹处理完毕!所有的.txt文件都生成了对应的.log文件了”,就算是成功运行了。如果你的txt分布在不同的文件夹,你就继续把这个脚本拷贝到其他的文件夹去运行或者让其他的txt到脚本所在的文件夹来。如果你是Windows XP的话,就直接成功了。而你如果是Windows Vista或Windows 7的话,它们都往往不能直接运行VBS(VBscript)脚本的,所以,我用“vbs转exe程序”把我写的vbs脚本也变成了一个标准的exe,是独立运行了,而不需要借助system32文件夹中的wscript.exe或cscript.exe来运行了。你的win7或Vista不能运行我的vbs脚本的话就用vbs转换的exe吧,双击就运行了。【备注:对着vbs文件,点右键,选择“编辑”或“打开方式”为“记事本”,就能查看vbs的源代码了】
下载“vbs转exe程序”,是在
http://ishare.iask.sina.com.cn/f/6503634.html?from=like
整个vbs的完整代码如下……
-------------------------
Set fso1 = CreateObject("scripting.filesystemobject")
For Each file1 In fso1.GetFolder(".").Files
If Right(file1.Name, 4) = ".txt" Then
Set old_file = fso1.OpenTextFile(Left(file1.Name, Len(file1.Name) - 4) & ".txt")
Set new_file = fso1.CreateTextFile(Left(file1.Name, Len(file1.Name) - 4) & ".log")
the_line = old_file.ReadLine
border_position = InStr(1, the_line, "=")
new_tail = "/n/" & Left(the_line, border_position - 1) & " "
new_file.WriteLine (Replace(Trim(Right(the_line, Len(the_line) - border_position)) & " ", " ", new_tail))
old_file.Close
new_file.Close
Set old_file = Nothing
Set new_file = Nothing
End If
Next
MsgBox "本文件夹处理完毕!所有的.txt文件都生成了对应的.log文件了"
------------------
vbs是vbscript的缩写,是微软公司的专利技术,用来进行网站后台或网页前端的编程,也可以用来进行各种Windows的自动化管理,包括对文本文件或大型XML语料库的任意操作(增删查改)。“*.vbs”文件的运行,总是依赖c:\windows\system32\wscript.exe或cscript.exe。如果杀毒软件禁止了或你删除了这两个exe的话,vbs脚本就无法运行了,不过,通常不会出现这种情况的。其实,vbs编程蕴藏着正则表达式和数据库访问和互联网通信的全面功能,也能轻松编写出“抓取网页语料而自动保存到本地的智能化爬虫”呢,所以,优盘上呀,移动硬盘呀,往往变成了vbs编写的病毒的泛滥之地。VBS的语法就是BASIC,是微软血脉的BASIC版本的网页版兼本地版,而VBA则是微软血脉的BASIC版本的“Office嵌入版(必须依赖且运行于Office软件)”。从功能强弱与学习难度的角度,我们可以把VB叫做“大哥”,VBS叫做“二哥”,VBA叫做“三哥”,对了,“VB.NET”就是“大哥大”了,嘻嘻
附件
Last edited:
李亮1975重庆
语料库快乐军政委
IE的百度的自动变化vbs.vbs
这个脚本,运行一下,就会看到IE自动打开且访问“百度”网站,同时,其页面上的“新闻”两个字竟然瞬间被改变被篡改为了“旧闻”这两个字,且这个“旧闻”你用鼠标一点就发现是转向了“http://www.corpus4u.org/”这个网站哟,而百度的搜索文本框也被自动填入了“语料库语言学”这六个汉字,并且在页面的顶部中央被强行呈现了“VBS很强大呢!”这些字,就在你观察与惊讶的时候,这个IE呈现了7秒钟之后就自动跳转到“http://www.sohu.com”呢,到了这个页面,保留5秒钟,当前的这个IE窗体就自动关闭退出了,这些操作的自动执行体现了VBS的强大。源代码如下:
----------------
Set myie = CreateObject("InternetExplorer.Application")
myie.Visible = True
myie.navigate "http://www.baidu.com"
Do
Loop Until myie.readyState = 4 ' READYSTATE_COMPLETE = 4
myie.Document.getElementById("nv").FirstChild.innerText = "旧闻"
myie.Document.getElementById("nv").FirstChild.href = "http://www.corpus4u.org/"
myie.Document.getElementById("kw").Value = "语料库语言学"
myie.Document.body.insertAdjacentHTML "afterbegin", "<b>VBS很强大呢!</b>"
wscript.sleep 7000
myie.navigate "http://www.sohu.com"
wscript.sleep 5000
myie.Quit
---------------
同样,附件中就是以上的VBS代码,你解压缩出来之后,双击就运行了。或者你把上面的代码拷贝到一个txt文件,然后把这个txt文件的文件扩展名改为vbs(点右键选择重命名,如果看不到文件扩展名就需要从资源管理器的“文件夹选项”菜单进行“显示文件扩展名”的操作)。附件中的“执行效果的屏幕画面.jpg”也欢迎一瞥。
这个脚本,运行一下,就会看到IE自动打开且访问“百度”网站,同时,其页面上的“新闻”两个字竟然瞬间被改变被篡改为了“旧闻”这两个字,且这个“旧闻”你用鼠标一点就发现是转向了“http://www.corpus4u.org/”这个网站哟,而百度的搜索文本框也被自动填入了“语料库语言学”这六个汉字,并且在页面的顶部中央被强行呈现了“VBS很强大呢!”这些字,就在你观察与惊讶的时候,这个IE呈现了7秒钟之后就自动跳转到“http://www.sohu.com”呢,到了这个页面,保留5秒钟,当前的这个IE窗体就自动关闭退出了,这些操作的自动执行体现了VBS的强大。源代码如下:
----------------
Set myie = CreateObject("InternetExplorer.Application")
myie.Visible = True
myie.navigate "http://www.baidu.com"
Do
Loop Until myie.readyState = 4 ' READYSTATE_COMPLETE = 4
myie.Document.getElementById("nv").FirstChild.innerText = "旧闻"
myie.Document.getElementById("nv").FirstChild.href = "http://www.corpus4u.org/"
myie.Document.getElementById("kw").Value = "语料库语言学"
myie.Document.body.insertAdjacentHTML "afterbegin", "<b>VBS很强大呢!</b>"
wscript.sleep 7000
myie.navigate "http://www.sohu.com"
wscript.sleep 5000
myie.Quit
---------------
同样,附件中就是以上的VBS代码,你解压缩出来之后,双击就运行了。或者你把上面的代码拷贝到一个txt文件,然后把这个txt文件的文件扩展名改为vbs(点右键选择重命名,如果看不到文件扩展名就需要从资源管理器的“文件夹选项”菜单进行“显示文件扩展名”的操作)。附件中的“执行效果的屏幕画面.jpg”也欢迎一瞥。
附件

回复: 如何写正则表达式
这个似乎不能一步到位 建议写个小程序
先取出等号前面的部分 读入变量$a 同时删除$a=
然后把等号后面的部分读入一个字符串 再以空格为分隔符将其转换为列表 在每个元素后面加上/n/$a
我这里有许多文件,每个文件只有一行,格式如下:
Fa01M04= 劳力 劳动力 工作者
我的目的是通过正则表达式的替换功能,将之变成:劳力/n/Fa01M04 劳动力/n/Fa01M04 工作者/n/Fa01M04
不知如何书写正则表达式,请C友赐教,谢谢!
这个似乎不能一步到位 建议写个小程序
先取出等号前面的部分 读入变量$a 同时删除$a=
然后把等号后面的部分读入一个字符串 再以空格为分隔符将其转换为列表 在每个元素后面加上/n/$a
Last edited:
李亮1975重庆
语料库快乐军政委
我首次提供的小程序是假设要处理的txt文件的文字编码是ANSI
我们用“记事本”打开一个txt,然后点“另存为”就会看到“编码”这个下拉菜单有4个选择:ANSI,UNICODE,UNICODE BIG,UTF-8。我做首次提供的小程序的时候是假设的ANSI,也用的是ANSI来测试的。你看看你的txt是哪种文字编码吧?否则我就需要添加一个自动判断一个txt文件的文字编码的功能了,当然也许你的txt文件有多种编码并存,也许真的有必要弄个自动的文字编码判断的功能出来。
用你的原文和乱码进行对比测试了,你的编码应该是UTF-8。而我的程序除了ANSI不乱码,其他编码都乱码的。
金山毒霸被誉为“国产杀毒软件的误杀之王”,它甚至自己杀自己的胳膊腿与器官呢。你可以重新下载我的exe文件,下载之前,把金山毒霸暂时关闭掉,然后下载之后,在VirusTotal这个在线网站进行几十款杀毒软件对我的exe的“集体裁决”,你点页面的文件选择对话框,就从本地选择了我的exe文件,然后上传就开始自动被几十款国内外的杀毒软件的最新引擎进行分析了,最后会呈现出“总报告”,从这个报告你会发现:同一个病毒总是被不同的杀毒软件命名为不同的病毒名称。VirusTotal的中文版的网址如下:
https://www.virustotal.com/zh-cn/
哇,我测试了一下,竟然42款杀毒软件之中有30款软件认为我的EXE是病毒呢,看来我需要找另一款“VBS转EXE”的软件进行转换,这类软件有多款的。嗯,VirusTotal的报告如下:
(黑色行,是不认为是病毒的意思)
AhnLab-V3 Win-Trojan/Agent.8929.C 20120530
AntiVir PCK/UPACK 20120531
Antiy-AVL Trojan/Win32.Agent.gen 20120531
Avast - 20120530
AVG Suspicion: unknown virus 20120530
BitDefender Trojan.Generic.7296187 20120531
ByteHero - 20120522
CAT-QuickHeal (Suspicious) - DNAScan 20120530
ClamAV Trojan.Onlinegames-2021 20120531
Commtouch W32/SuspPack.CY.gen!Eldorado 20120531
Comodo Packed.Win32.MUPACK.~KW 20120531
DrWeb Trojan.Uploader.24580 20120531
Emsisoft Trojan-Downloader.Win32.Small!IK 20120531
eSafe Win32.Trojan 20120530
F-Prot W32/SuspPack.CY.gen!Eldorado 20120530
F-Secure Trojan.Generic.7296187 20120531
Fortinet - 20120531
GData Trojan.Generic.7296187 20120531
Ikarus Trojan-Downloader.Win32.Small 20120531
Jiangmin TrojanDropper.Agent.aehe 20120531
K7AntiVirus Trojan-Downloader 20120530
Kaspersky - 20120531
McAfee - 20120531
McAfee-GW-Edition - 20120530
Microsoft PWS:Win32/Ldpinch.BL 20120530
NOD32 Win32/Agent.OHT 20120530
Norman W32/Packed_Upack.A 20120530
nProtect Trojan.Generic.7296187 20120530
Panda - 20120530
PCTools HeurEngine.ZeroDayThreat 20120531
Rising - 20120531
Sophos - 20120531
SUPERAntiSpyware - 20120531
Symantec Suspicious.MH690.A 20120531
TheHacker Trojan/Agent.aon 20120531
TotalDefense - 20120530
TrendMicro Cryp_Xed-12 20120531
TrendMicro-HouseCall Cryp_Xed-12 20120530
VBA32 - 20120530
VIPRE Trojan.Win32.Packer.Upack0.3.9 (ep) 20120531
ViRobot Packed.Win32.UPack 20120531
VirusBuster Trojan.Agent!CXir7UGfi64 20120530
李博士您好,使用您提供的小程序,有些小问题:
如原文件: Aa01A01= 人 士 人物 人士 人氏 人选
执行后:浜?澹?浜虹墿/n/Aa01A01 浜哄+/n/Aa01A01 浜烘皬/n/Aa01A01 浜洪??/n/Aa01A01
不知为什么?请解答,谢谢!
另:在运行.exe文件时,还没有运行,金山素霸就给清理了。
我们用“记事本”打开一个txt,然后点“另存为”就会看到“编码”这个下拉菜单有4个选择:ANSI,UNICODE,UNICODE BIG,UTF-8。我做首次提供的小程序的时候是假设的ANSI,也用的是ANSI来测试的。你看看你的txt是哪种文字编码吧?否则我就需要添加一个自动判断一个txt文件的文字编码的功能了,当然也许你的txt文件有多种编码并存,也许真的有必要弄个自动的文字编码判断的功能出来。
用你的原文和乱码进行对比测试了,你的编码应该是UTF-8。而我的程序除了ANSI不乱码,其他编码都乱码的。
金山毒霸被誉为“国产杀毒软件的误杀之王”,它甚至自己杀自己的胳膊腿与器官呢。你可以重新下载我的exe文件,下载之前,把金山毒霸暂时关闭掉,然后下载之后,在VirusTotal这个在线网站进行几十款杀毒软件对我的exe的“集体裁决”,你点页面的文件选择对话框,就从本地选择了我的exe文件,然后上传就开始自动被几十款国内外的杀毒软件的最新引擎进行分析了,最后会呈现出“总报告”,从这个报告你会发现:同一个病毒总是被不同的杀毒软件命名为不同的病毒名称。VirusTotal的中文版的网址如下:
https://www.virustotal.com/zh-cn/
哇,我测试了一下,竟然42款杀毒软件之中有30款软件认为我的EXE是病毒呢,看来我需要找另一款“VBS转EXE”的软件进行转换,这类软件有多款的。嗯,VirusTotal的报告如下:
(黑色行,是不认为是病毒的意思)
AhnLab-V3 Win-Trojan/Agent.8929.C 20120530
AntiVir PCK/UPACK 20120531
Antiy-AVL Trojan/Win32.Agent.gen 20120531
Avast - 20120530
AVG Suspicion: unknown virus 20120530
BitDefender Trojan.Generic.7296187 20120531
ByteHero - 20120522
CAT-QuickHeal (Suspicious) - DNAScan 20120530
ClamAV Trojan.Onlinegames-2021 20120531
Commtouch W32/SuspPack.CY.gen!Eldorado 20120531
Comodo Packed.Win32.MUPACK.~KW 20120531
DrWeb Trojan.Uploader.24580 20120531
Emsisoft Trojan-Downloader.Win32.Small!IK 20120531
eSafe Win32.Trojan 20120530
F-Prot W32/SuspPack.CY.gen!Eldorado 20120530
F-Secure Trojan.Generic.7296187 20120531
Fortinet - 20120531
GData Trojan.Generic.7296187 20120531
Ikarus Trojan-Downloader.Win32.Small 20120531
Jiangmin TrojanDropper.Agent.aehe 20120531
K7AntiVirus Trojan-Downloader 20120530
Kaspersky - 20120531
McAfee - 20120531
McAfee-GW-Edition - 20120530
Microsoft PWS:Win32/Ldpinch.BL 20120530
NOD32 Win32/Agent.OHT 20120530
Norman W32/Packed_Upack.A 20120530
nProtect Trojan.Generic.7296187 20120530
Panda - 20120530
PCTools HeurEngine.ZeroDayThreat 20120531
Rising - 20120531
Sophos - 20120531
SUPERAntiSpyware - 20120531
Symantec Suspicious.MH690.A 20120531
TheHacker Trojan/Agent.aon 20120531
TotalDefense - 20120530
TrendMicro Cryp_Xed-12 20120531
TrendMicro-HouseCall Cryp_Xed-12 20120530
VBA32 - 20120530
VIPRE Trojan.Win32.Packer.Upack0.3.9 (ep) 20120531
ViRobot Packed.Win32.UPack 20120531
VirusBuster Trojan.Agent!CXir7UGfi64 20120530
Last edited:
李亮1975重庆
语料库快乐军政委
TXT转ANSI之李亮版.zip
把Unicode或UTF-8或Unicode big endian的文字编码的txt文件进行批量转换,让同一个文件夹中的所有txt文件都瞬间变成ANSI编码,是语料库建设的优秀工具,速度快,小巧,经过VirusTotal的42款杀毒引擎的检测而100%无毒,可以从新浪爱问共享下载:
http://ishare.iask.sina.com.cn/f/24718343.html
TXT转ANSI之李亮版.zip (已经删除了,误做成只读取一行的功能了)
http://ishare.iask.sina.com.cn/f/24718887.html
TXT转Unicode之李亮版.zip (已经删除了,误做成只读取一行的功能了)
http://ishare.iask.sina.com.cn/f/24718907.html
TXT转Unicode big endian之李亮版.zip (已经删除了,误做成只读取一行的功能了)
http://ishare.iask.sina.com.cn/f/24719317.html
TXT转UTF-8之李亮版.zip (已经删除了,误做成只读取一行的功能了)
查询资料之后,发现VBS似乎无法轻松地读写UTF-8文字编码且含有汉字的txt文件,因为它的opentextfile()只能读写ANSI,Unicode两种编码。
测试了几款VBS转换为EXE的小工具,发现都难以做到100%的几十款杀毒引擎的不报毒。
所以,干脆就“TXT转ANSI之李亮版.zip”,然后再用VBS来处理吧。我这里,又改进了一点点那个VBS。代码如下……
----------------
' 新增:对于不含有等于号的文件,就自动不处理了。
MsgBox "本程序只支持ANSI编码的TXT。其他编码的TXT,请使用<李亮版txt转码系列工具>,转换为ANSI", vbInformation
Set fso1 = CreateObject("scripting.filesystemobject")
For Each file1 In fso1.GetFolder(".").Files
If Right(file1.Name, 4) = ".txt" Then
Set old_file = fso1.opentextfile(Left(file1.Name, Len(file1.Name) - 4) & ".txt")
the_line = old_file.readline
border_position = InStr(1, the_line, "=")
If border_position > 0 Then
Set new_file = fso1.createtextfile(Left(file1.Name, Len(file1.Name) - 4) & ".log")
new_tail = "/n/" & Left(the_line, border_position - 1) & " "
new_file.writeline (Replace(Trim(Right(the_line, Len(the_line) - border_position)) & " ", " ", new_tail))
new_file.Close
Set new_file = Nothing
End If
old_file.Close
Set old_file = Nothing
End If
Next
MsgBox "本文件夹处理完毕!所有的.txt文件都生成了对应的.log文件了", vbInformation
----------------
把Unicode或UTF-8或Unicode big endian的文字编码的txt文件进行批量转换,让同一个文件夹中的所有txt文件都瞬间变成ANSI编码,是语料库建设的优秀工具,速度快,小巧,经过VirusTotal的42款杀毒引擎的检测而100%无毒,可以从新浪爱问共享下载:
http://ishare.iask.sina.com.cn/f/24718343.html
TXT转ANSI之李亮版.zip (已经删除了,误做成只读取一行的功能了)
http://ishare.iask.sina.com.cn/f/24718887.html
TXT转Unicode之李亮版.zip (已经删除了,误做成只读取一行的功能了)
http://ishare.iask.sina.com.cn/f/24718907.html
TXT转Unicode big endian之李亮版.zip (已经删除了,误做成只读取一行的功能了)
http://ishare.iask.sina.com.cn/f/24719317.html
TXT转UTF-8之李亮版.zip (已经删除了,误做成只读取一行的功能了)
查询资料之后,发现VBS似乎无法轻松地读写UTF-8文字编码且含有汉字的txt文件,因为它的opentextfile()只能读写ANSI,Unicode两种编码。
测试了几款VBS转换为EXE的小工具,发现都难以做到100%的几十款杀毒引擎的不报毒。
所以,干脆就“TXT转ANSI之李亮版.zip”,然后再用VBS来处理吧。我这里,又改进了一点点那个VBS。代码如下……
----------------
' 新增:对于不含有等于号的文件,就自动不处理了。
MsgBox "本程序只支持ANSI编码的TXT。其他编码的TXT,请使用<李亮版txt转码系列工具>,转换为ANSI", vbInformation
Set fso1 = CreateObject("scripting.filesystemobject")
For Each file1 In fso1.GetFolder(".").Files
If Right(file1.Name, 4) = ".txt" Then
Set old_file = fso1.opentextfile(Left(file1.Name, Len(file1.Name) - 4) & ".txt")
the_line = old_file.readline
border_position = InStr(1, the_line, "=")
If border_position > 0 Then
Set new_file = fso1.createtextfile(Left(file1.Name, Len(file1.Name) - 4) & ".log")
new_tail = "/n/" & Left(the_line, border_position - 1) & " "
new_file.writeline (Replace(Trim(Right(the_line, Len(the_line) - border_position)) & " ", " ", new_tail))
new_file.Close
Set new_file = Nothing
End If
old_file.Close
Set old_file = Nothing
End If
Next
MsgBox "本文件夹处理完毕!所有的.txt文件都生成了对应的.log文件了", vbInformation
----------------
附件
Last edited:
回复: TXT转ANSI之李亮版.zip
谢谢李博,测试成功,顺手牵羊还收获了编码转换程序,哈哈! 再次感谢,必须的。
把Unicode或UTF-8或Unicode big endian的文字编码的txt文件进行批量转换,让同一个文件夹中的所有txt文件都瞬间变成ANSI编码,是语料库建设的优秀工具,速度快,小巧,经过VirusTotal的42款杀毒引擎的检测而100%无毒,可以从新浪爱问共享下载:
http://ishare.iask.sina.com.cn/f/24718343.html
TXT转ANSI之李亮版.zip
http://ishare.iask.sina.com.cn/f/24718887.html
TXT转Unicode之李亮版.zip
http://ishare.iask.sina.com.cn/f/24718907.html
TXT转Unicode big endian之李亮版.zip
http://ishare.iask.sina.com.cn/f/24719317.html
TXT转UTF-8之李亮版.zip
查询资料之后,发现VBS似乎无法轻松地读写UTF-8文字编码且含有汉字的txt文件,因为它的opentextfile()只能读写ANSI,Unicode两种编码。
测试了几款VBS转换为EXE的小工具,发现都难以做到100%的几十款杀毒引擎的不报毒。
所以,干脆就“TXT转ANSI之李亮版.zip”,然后再用VBS来处理吧。我这里,又改进了一点点那个VBS。代码如下……
----------------
' 新增:对于不含有等于号的文件,就自动不处理了。
MsgBox "本程序只支持ANSI编码的TXT。其他编码的TXT,请使用<李亮版txt转码系列工具>,转换为ANSI", vbInformation
Set fso1 = CreateObject("scripting.filesystemobject")
For Each file1 In fso1.GetFolder(".").Files
If Right(file1.Name, 4) = ".txt" Then
Set old_file = fso1.opentextfile(Left(file1.Name, Len(file1.Name) - 4) & ".txt")
the_line = old_file.readline
border_position = InStr(1, the_line, "=")
If border_position > 0 Then
Set new_file = fso1.createtextfile(Left(file1.Name, Len(file1.Name) - 4) & ".log")
new_tail = "/n/" & Left(the_line, border_position - 1) & " "
new_file.writeline (Replace(Trim(Right(the_line, Len(the_line) - border_position)) & " ", " ", new_tail))
new_file.Close
Set new_file = Nothing
End If
old_file.Close
Set old_file = Nothing
End If
Next
MsgBox "本文件夹处理完毕!所有的.txt文件都生成了对应的.log文件了", vbInformation
----------------
谢谢李博,测试成功,顺手牵羊还收获了编码转换程序,哈哈! 再次感谢,必须的。
李亮1975重庆
语料库快乐军政委
Word创建与自动操控vbs.vbs
附件中的“Word创建与自动操控vbs.vbs”的源代码是演示VBS语言的强大与灵活,内容如下:
Set my_word=CreateObject("word.application")
Set WshShell = WScript.CreateObject("WScript.Shell")
my_word.visible=true
my_word.documents.add
my_word.ActiveDocument.range.text="Corpus Linguistics for you"
my_word.ActiveDocument.range.words(2).font.size=30
my_word.ActiveDocument.saveas WshShell.CurrentDirectory & "\1.doc"
MsgBox "单词总量为:" & my_word.ActiveDocument.words.count-1
wscript.sleep 10000
my_word.ActiveDocument.close
第1句是借助Windows的COM(component object model)技术而创建出虚拟的一个microsoft word程序;
第2句是借助wscript这个VBS的全局型变量对象而创建出“Wscript.shell”,借助它就能倒计时或延时,或者计算出当前程序所在的文件夹位置;
第3句是让创建的虚拟的一个MS Word程序的窗体变得可见,如果“visible=false”或不写第3句的话,就是“继续让这个虚拟的Word程序保持隐身状态而做事哟”;
第4句是新建一个空白文档;
第5句是自动在新建的空白文档的正文输入一些文字;
第6句是让第2个单词的字号为30;
第7句的WshShell.CurrentDirectory是计算当前程序所在的文件夹位置,同时保存当前没有被保存的文件;
第8句是计算单词总量,因为空白文件总是至少有个“回车符”且被当作1个单词的,所以ActiveDocument.words.count所代表的单词总量就要扣除1;
第9句是借助”延时”或“倒计时”10秒之后就执行下一句;
第10句是关闭当前文件,但保留Microsoft Word的主程序窗体。
进一步来说,我们语料库语言学工程中就可以借助MS Word的强大的“字符、字、词、句、段落”对象模型来制作“tokenizer, sentence splitter, paragraph detecter, XML annotator, XML tag analyzer, KeyWord In Sentence extractor, N-gram generator, wordlist generator, sentencelist generator, corpus joiner, corpus splitter, annotation remover, annotation tag lister, average word frequency calculator”。
VBScript编程语言,无需专门的编辑器,仅仅新建一个“纯文本文件”,双击之后在“记事本”中继续编写就可以出笼,写好之后,把文件扩展名改为.vbs,就能双击运行了,就算是有程序错误也能在运行时被提示在哪一行呢,堪称“语料库编程的最高级的空手道”。微软公司是VBS编程语言的专利方,专门的完整参考手册的网址如下:
http://msdn.microsoft.com/en-us/library/t0aew7h6(VS.85).aspx
附件中的“Word创建与自动操控vbs.vbs”的源代码是演示VBS语言的强大与灵活,内容如下:
Set my_word=CreateObject("word.application")
Set WshShell = WScript.CreateObject("WScript.Shell")
my_word.visible=true
my_word.documents.add
my_word.ActiveDocument.range.text="Corpus Linguistics for you"
my_word.ActiveDocument.range.words(2).font.size=30
my_word.ActiveDocument.saveas WshShell.CurrentDirectory & "\1.doc"
MsgBox "单词总量为:" & my_word.ActiveDocument.words.count-1
wscript.sleep 10000
my_word.ActiveDocument.close
第1句是借助Windows的COM(component object model)技术而创建出虚拟的一个microsoft word程序;
第2句是借助wscript这个VBS的全局型变量对象而创建出“Wscript.shell”,借助它就能倒计时或延时,或者计算出当前程序所在的文件夹位置;
第3句是让创建的虚拟的一个MS Word程序的窗体变得可见,如果“visible=false”或不写第3句的话,就是“继续让这个虚拟的Word程序保持隐身状态而做事哟”;
第4句是新建一个空白文档;
第5句是自动在新建的空白文档的正文输入一些文字;
第6句是让第2个单词的字号为30;
第7句的WshShell.CurrentDirectory是计算当前程序所在的文件夹位置,同时保存当前没有被保存的文件;
第8句是计算单词总量,因为空白文件总是至少有个“回车符”且被当作1个单词的,所以ActiveDocument.words.count所代表的单词总量就要扣除1;
第9句是借助”延时”或“倒计时”10秒之后就执行下一句;
第10句是关闭当前文件,但保留Microsoft Word的主程序窗体。
进一步来说,我们语料库语言学工程中就可以借助MS Word的强大的“字符、字、词、句、段落”对象模型来制作“tokenizer, sentence splitter, paragraph detecter, XML annotator, XML tag analyzer, KeyWord In Sentence extractor, N-gram generator, wordlist generator, sentencelist generator, corpus joiner, corpus splitter, annotation remover, annotation tag lister, average word frequency calculator”。
VBScript编程语言,无需专门的编辑器,仅仅新建一个“纯文本文件”,双击之后在“记事本”中继续编写就可以出笼,写好之后,把文件扩展名改为.vbs,就能双击运行了,就算是有程序错误也能在运行时被提示在哪一行呢,堪称“语料库编程的最高级的空手道”。微软公司是VBS编程语言的专利方,专门的完整参考手册的网址如下:
http://msdn.microsoft.com/en-us/library/t0aew7h6(VS.85).aspx
附件
Last edited:
李亮1975重庆
语料库快乐军政委
TXT全能转码之李亮版.zip
高速简洁小巧免费的文本小工具。一次选中同一文件夹的所有txt文件,但不包括子文件夹的,进行ANSI、UTF-8、Unicode、Unicode big endian之间的互相转换,适合语料库建设或掌上阅读器的专门编码需求。
经过VirusTotal的42款杀毒引擎的分析而100%无毒。
这次是一次处理每个文件的全部内容了,而不是仅仅第一行而已。
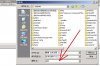
附件中的“如何查看txt的文字编码.jpg”,是你在双击打开一个纯文本文件之后,点“另存为”菜单,就看到的“文字编码”,这个技能挺重要的,能有效地解决你的检索工具为何无法检索,你如何在AntConc中选择正确的文字编码的问题。
高速简洁小巧免费的文本小工具。一次选中同一文件夹的所有txt文件,但不包括子文件夹的,进行ANSI、UTF-8、Unicode、Unicode big endian之间的互相转换,适合语料库建设或掌上阅读器的专门编码需求。
经过VirusTotal的42款杀毒引擎的分析而100%无毒。
这次是一次处理每个文件的全部内容了,而不是仅仅第一行而已。
附件中的“如何查看txt的文字编码.jpg”,是你在双击打开一个纯文本文件之后,点“另存为”菜单,就看到的“文字编码”,这个技能挺重要的,能有效地解决你的检索工具为何无法检索,你如何在AntConc中选择正确的文字编码的问题。
附件
Last edited:
李亮1975重庆
语料库快乐军政委
JustTheWord的搭配抓取vbs.vbs
http://www.just-the-word.com/ 是基于BNC(British National Corpus)的其中8千万词的一个搭配查询与分析呈现的语料库,但是,查询结果并不能直接进行单独保存,只能用手工进行分段拷贝,而VBS正好可以进行集中抓取,源代码如下:
----------
Set myie = CreateObject("InternetExplorer.Application")
Set myie2 = CreateObject("InternetExplorer.Application")
myie.left=1
myie.top=1
myie.height=600
myie.width=500
myie2.left=501
myie2.top=1
myie2.height=600
myie2.width=500
your_word=inputbox("您的搜索词(组)是:","JustTheWord之搭配抓取器 李亮制作","totally")
your_word=replace(trim(your_word)," ", "+")
myie.Visible = True
myie.navigate "http://www.just-the-word.com/main.pl?word=" & your_word
Do
Loop Until myie.readyState = 4 ' READYSTATE_COMPLETE = 4
the_number=myie.Document.body.getElementsBytagName("span").length
for counter=0 to the_number-1
if myie.Document.body.getElementsBytagName("span")(counter).className="collocstring" then
result_string=result_string & "<div>" & myie.Document.body.getElementsBytagName("span")(counter).innerText & "</div>"
end if
next
myie2.visible=true
myie2.navigate "about:blank"
myie2.document.write "<body>" & result_string & "</body>"
----------
运行起来之后,你只需要输入一个单词或词组,回车,稍等片刻就会看到有两个IE窗口自动弹出,左侧的IE窗口是JustTheWord网站的查询结果,右侧是VBS的集中抓取效果。一旦右侧窗口弹出且呈现了数据,程序就算是运行完毕,你就可以手工拷贝已经自动地集中排列的搭配列表了。
http://www.just-the-word.com/ 是基于BNC(British National Corpus)的其中8千万词的一个搭配查询与分析呈现的语料库,但是,查询结果并不能直接进行单独保存,只能用手工进行分段拷贝,而VBS正好可以进行集中抓取,源代码如下:
----------
Set myie = CreateObject("InternetExplorer.Application")
Set myie2 = CreateObject("InternetExplorer.Application")
myie.left=1
myie.top=1
myie.height=600
myie.width=500
myie2.left=501
myie2.top=1
myie2.height=600
myie2.width=500
your_word=inputbox("您的搜索词(组)是:","JustTheWord之搭配抓取器 李亮制作","totally")
your_word=replace(trim(your_word)," ", "+")
myie.Visible = True
myie.navigate "http://www.just-the-word.com/main.pl?word=" & your_word
Do
Loop Until myie.readyState = 4 ' READYSTATE_COMPLETE = 4
the_number=myie.Document.body.getElementsBytagName("span").length
for counter=0 to the_number-1
if myie.Document.body.getElementsBytagName("span")(counter).className="collocstring" then
result_string=result_string & "<div>" & myie.Document.body.getElementsBytagName("span")(counter).innerText & "</div>"
end if
next
myie2.visible=true
myie2.navigate "about:blank"
myie2.document.write "<body>" & result_string & "</body>"
----------
运行起来之后,你只需要输入一个单词或词组,回车,稍等片刻就会看到有两个IE窗口自动弹出,左侧的IE窗口是JustTheWord网站的查询结果,右侧是VBS的集中抓取效果。一旦右侧窗口弹出且呈现了数据,程序就算是运行完毕,你就可以手工拷贝已经自动地集中排列的搭配列表了。
附件
回复: TXT全能转码之李亮版.zip
非常感谢李博士的小巧实用程序,既能处理汉语,又能处理英语。
没有想到文本处理有这么多的秘密!!
高速简洁小巧免费的文本小工具。一次选中同一文件夹的所有txt文件,但不包括子文件夹的,进行ANSI、UTF-8、Unicode、Unicode big endian之间的互相转换,适合语料库建设或掌上阅读器的专门编码需求。
经过VirusTotal的42款杀毒引擎的分析而100%无毒。
这次是一次处理每个文件的全部内容了,而不是仅仅第一行而已。
附件中的“如何查看txt的文字编码.jpg”,是你在双击打开一个纯文本文件之后,点“另存为”菜单,就看到的“文字编码”,这个技能挺重要的,能有效地解决你的检索工具为何无法检索,你如何在AntConc中选择正确的文字编码的问题。
非常感谢李博士的小巧实用程序,既能处理汉语,又能处理英语。
没有想到文本处理有这么多的秘密!!
李亮1975重庆
语料库快乐军政委
文字编码批量判断器李亮版.rar
高速免费的文本小工具,对同一文件夹(不含子文件夹)的所有.txt与.htm与.html文件处理,进行ANSI、UTF-8、Unicode、 Unicode big endian的自动判断,最后生成report.log,集中汇报所有匹配文件的文字编码,适合语料库建设或掌上阅读器的专门编码需求。经 VirusTotal的42款杀毒引擎检测而100%无毒。report.log的格式如下:
--- D:\ ---
ANSI --- a.htm
Unicode --- c.htm
Unicode big endian --- b.txt
UTF-8 --- c.txt
在你收集下载了一大堆的txt文件呀,htm文件呀,html文件呀,你懒得一个一个地用“记事本”打开而点“另存为”来查看“文字编码”到底是“四大编码之哪一码”的时候,本软件就是最佳选择了。
高速免费的文本小工具,对同一文件夹(不含子文件夹)的所有.txt与.htm与.html文件处理,进行ANSI、UTF-8、Unicode、 Unicode big endian的自动判断,最后生成report.log,集中汇报所有匹配文件的文字编码,适合语料库建设或掌上阅读器的专门编码需求。经 VirusTotal的42款杀毒引擎检测而100%无毒。report.log的格式如下:
--- D:\ ---
ANSI --- a.htm
Unicode --- c.htm
Unicode big endian --- b.txt
UTF-8 --- c.txt
在你收集下载了一大堆的txt文件呀,htm文件呀,html文件呀,你懒得一个一个地用“记事本”打开而点“另存为”来查看“文字编码”到底是“四大编码之哪一码”的时候,本软件就是最佳选择了。
附件
李亮1975重庆
语料库快乐军政委
TXT全角半角批量互转器李亮版.rar
高速免费的文本小工具,对同一文件夹(含子文件夹)的所有.txt文件本身进行半角到全角或全角到半角的编码转换,适合语料库建设或掌上阅读器的专门编码需求。例如,“ab78?!电”变成全角就是“ab78?!电”。运行前,请确保TXT是ANSI编码,其他编码将无法转换,而汉语句号转换为半角就变成英语问号且无法修复。经VirusTotal的42款杀毒引擎检测而100%无毒。
我们收集或搜集的txt文件往往是多种来源和多种操作而形成的,文字编码往往不一样,这个文件可能属于ANSI,那个文件可能属于UTF-8,另外一个又属于Unicode,而全角半角的混杂往往是造成语料库乱码的主要原因,往往全角半角的混杂也造成检索软件的紊乱,而我们平时英语输入或中文输入的时候的切换输入法的瞬间操作的不起眼的小失误往往就造成了“中英文标点”的“杂居”,例如:英语句子含有了一个或一些中文逗号……
高速免费的文本小工具,对同一文件夹(含子文件夹)的所有.txt文件本身进行半角到全角或全角到半角的编码转换,适合语料库建设或掌上阅读器的专门编码需求。例如,“ab78?!电”变成全角就是“ab78?!电”。运行前,请确保TXT是ANSI编码,其他编码将无法转换,而汉语句号转换为半角就变成英语问号且无法修复。经VirusTotal的42款杀毒引擎检测而100%无毒。
我们收集或搜集的txt文件往往是多种来源和多种操作而形成的,文字编码往往不一样,这个文件可能属于ANSI,那个文件可能属于UTF-8,另外一个又属于Unicode,而全角半角的混杂往往是造成语料库乱码的主要原因,往往全角半角的混杂也造成检索软件的紊乱,而我们平时英语输入或中文输入的时候的切换输入法的瞬间操作的不起眼的小失误往往就造成了“中英文标点”的“杂居”,例如:英语句子含有了一个或一些中文逗号……
附件
李亮1975重庆
语料库快乐军政委
英语N-gram生成器vbs.zip (N-gram就是“语块”啦,就是“无搜索词的语块”)
高速免费且开放源代码的文本小工具,双击即可运行的vbs脚本小程序,对同一文件夹(不含子文件夹)的所有.txt文件进行N-gram的生成与对应*.txt文件同名称却不同文件扩展名的*.log,例如“a.txt”的所有N-gram就生成在“a.log”这个文件了。
你可以从“新浪爱问”下载“英语N-gram生成器vbs.zip“,链接是
http://ishare.iask.sina.com.cn/f/24766658.html
本工具适合词汇搭配研究与语块提取的语料库的初步需求,并没有进行排序或频率计算或冗余剔除。如果你需要进一步处理,可以导入Microsoft Excel进行排序就可以按照字母顺序来观察了,或者进行“<高级筛选>的<选择不重复的记录>”的操作,就得到“不重复的有序化的语块列表”了。
没有采用复杂的分词机制,仅仅采用空格作为单词之间的切分标准,因此标点符号依然附着在某些单词的“身前身后”而形成一个“单词”。但是,自动以每个自然段作为N-gram的“生成边界”,而没有跨段生成N-gram(即,把某段的最后一个词跟下一段的第一个词视为一个连续的语块)。
对着脚本点右键,选择“编辑”或“打开方式”为“记事本”,就可以阅读源代码。
经 VirusTotal的42款杀毒引擎检测,只有2款杀毒软件报毒(嘻嘻,当代杀毒软件的智力呀)。这两款聪明的杀毒软件的“姓名”与“报告”如下:
Comodo TrojWare.JS.Agent.nge 20120602
McAfee-GW-Edition Heuristic.LooksLike.Win32.Suspicious.B 20120603
现在,假设我们有1.txt进行N-gram或“语块”的生成,而1.txt的内容如下:
Corpus linguistics is a good tool of research.
It can be "driven" and "based".
而运行本脚本,获取2个词到4个词之间的“语块”而生成的1.log则内容如下:
Corpus linguistics
linguistics is
is a
a good
good tool
tool of
of research.
Corpus linguistics is
linguistics is a
is a good
a good tool
good tool of
tool of research.
Corpus linguistics is a
linguistics is a good
is a good tool
a good tool of
good tool of research.
It can
can be
be "driven"
"driven" and
and "based".
It can be
can be "driven"
be "driven" and
"driven" and "based".
It can be "driven"
can be "driven" and
be "driven" and "based".
对上面的观察,能加深对语块的认识。
脚本的完整源代码如下……
Set fso1 = CreateObject("scripting.filesystemobject")
tip = "输入2,4表示2到4的N-gram" & Chr(13) & "输入3表示3个词的N-gram" & Chr(13) & "txt文件必须为ANSI文字编码,否则无法正常生成N-gram"
request = Trim(InputBox(tip, "用逗号表达的ngram范围 【李亮研发】", "2,4")) & ","
request = replace(request, " ", "")
If request = "," Then
MsgBox "您取消了程序"
bye = "yes"
End If
request = Split(request, ",")
If UBound(request) >= 1 And bye <> "yes" Then min = Abs(CInt(request(0))) Else min = 0
If UBound(request) >= 2 And bye <> "yes" Then max = Abs(CInt(request(1))) Else max = 0
If min = 0 Then
bye = "yes"
End If
If max < min Then max = min
If bye <> "yes" Then
For Each file1 In fso1.GetFolder(".").Files
If Right(file1.Name, 4) = ".txt" Then
Set old_file = fso1.OpenTextFile(Left(file1.Name, Len(file1.Name) - 4) & ".txt", 1, -2)
Set new_file = fso1.CreateTextFile(Left(file1.Name, Len(file1.Name) - 4) & ".log", True, False)
Do
the_line = Trim(old_file.ReadLine) & " "
the_array = Split(the_line, " ")
If UBound(the_array) >= min Then
For span = CInt(min) To CInt(max)
ngrams = ngrams & read_all_ngrams_from_array(the_array, span)
Next
End If
Loop Until old_file.AtEndOfStream
new_file.Write (ngrams)
ngrams = ""
old_file.Close
new_file.Close
Set old_file = Nothing
Set new_file = Nothing
End If
Next
MsgBox "本文件夹(不包括子文件夹)处理完毕!所有的.txt文件都生成了对应的.log文件了" & chr(13) & "李亮制作 2012年5月 广东外语外贸大学 词典学研究中心", vbinformation, "英语N-gram生成器.vbs"
End If
Function read_one_ngram_from_array(array1, start, span)
For counter = start To start + span - 1
Result = Result & array1(counter) & " "
Next
read_one_ngram_from_array = Result
End Function
Function read_all_ngrams_from_array(array1, span)
For counter = 0 To UBound(array1) - span
Result = Result & read_one_ngram_from_array(array1, counter, span) & Chr(13) & Chr(10)
Next
read_all_ngrams_from_array = Result
End Function
高速免费且开放源代码的文本小工具,双击即可运行的vbs脚本小程序,对同一文件夹(不含子文件夹)的所有.txt文件进行N-gram的生成与对应*.txt文件同名称却不同文件扩展名的*.log,例如“a.txt”的所有N-gram就生成在“a.log”这个文件了。
你可以从“新浪爱问”下载“英语N-gram生成器vbs.zip“,链接是
http://ishare.iask.sina.com.cn/f/24766658.html
本工具适合词汇搭配研究与语块提取的语料库的初步需求,并没有进行排序或频率计算或冗余剔除。如果你需要进一步处理,可以导入Microsoft Excel进行排序就可以按照字母顺序来观察了,或者进行“<高级筛选>的<选择不重复的记录>”的操作,就得到“不重复的有序化的语块列表”了。
没有采用复杂的分词机制,仅仅采用空格作为单词之间的切分标准,因此标点符号依然附着在某些单词的“身前身后”而形成一个“单词”。但是,自动以每个自然段作为N-gram的“生成边界”,而没有跨段生成N-gram(即,把某段的最后一个词跟下一段的第一个词视为一个连续的语块)。
对着脚本点右键,选择“编辑”或“打开方式”为“记事本”,就可以阅读源代码。
经 VirusTotal的42款杀毒引擎检测,只有2款杀毒软件报毒(嘻嘻,当代杀毒软件的智力呀)。这两款聪明的杀毒软件的“姓名”与“报告”如下:
Comodo TrojWare.JS.Agent.nge 20120602
McAfee-GW-Edition Heuristic.LooksLike.Win32.Suspicious.B 20120603
现在,假设我们有1.txt进行N-gram或“语块”的生成,而1.txt的内容如下:
Corpus linguistics is a good tool of research.
It can be "driven" and "based".
而运行本脚本,获取2个词到4个词之间的“语块”而生成的1.log则内容如下:
Corpus linguistics
linguistics is
is a
a good
good tool
tool of
of research.
Corpus linguistics is
linguistics is a
is a good
a good tool
good tool of
tool of research.
Corpus linguistics is a
linguistics is a good
is a good tool
a good tool of
good tool of research.
It can
can be
be "driven"
"driven" and
and "based".
It can be
can be "driven"
be "driven" and
"driven" and "based".
It can be "driven"
can be "driven" and
be "driven" and "based".
对上面的观察,能加深对语块的认识。
脚本的完整源代码如下……
Set fso1 = CreateObject("scripting.filesystemobject")
tip = "输入2,4表示2到4的N-gram" & Chr(13) & "输入3表示3个词的N-gram" & Chr(13) & "txt文件必须为ANSI文字编码,否则无法正常生成N-gram"
request = Trim(InputBox(tip, "用逗号表达的ngram范围 【李亮研发】", "2,4")) & ","
request = replace(request, " ", "")
If request = "," Then
MsgBox "您取消了程序"
bye = "yes"
End If
request = Split(request, ",")
If UBound(request) >= 1 And bye <> "yes" Then min = Abs(CInt(request(0))) Else min = 0
If UBound(request) >= 2 And bye <> "yes" Then max = Abs(CInt(request(1))) Else max = 0
If min = 0 Then
bye = "yes"
End If
If max < min Then max = min
If bye <> "yes" Then
For Each file1 In fso1.GetFolder(".").Files
If Right(file1.Name, 4) = ".txt" Then
Set old_file = fso1.OpenTextFile(Left(file1.Name, Len(file1.Name) - 4) & ".txt", 1, -2)
Set new_file = fso1.CreateTextFile(Left(file1.Name, Len(file1.Name) - 4) & ".log", True, False)
Do
the_line = Trim(old_file.ReadLine) & " "
the_array = Split(the_line, " ")
If UBound(the_array) >= min Then
For span = CInt(min) To CInt(max)
ngrams = ngrams & read_all_ngrams_from_array(the_array, span)
Next
End If
Loop Until old_file.AtEndOfStream
new_file.Write (ngrams)
ngrams = ""
old_file.Close
new_file.Close
Set old_file = Nothing
Set new_file = Nothing
End If
Next
MsgBox "本文件夹(不包括子文件夹)处理完毕!所有的.txt文件都生成了对应的.log文件了" & chr(13) & "李亮制作 2012年5月 广东外语外贸大学 词典学研究中心", vbinformation, "英语N-gram生成器.vbs"
End If
Function read_one_ngram_from_array(array1, start, span)
For counter = start To start + span - 1
Result = Result & array1(counter) & " "
Next
read_one_ngram_from_array = Result
End Function
Function read_all_ngrams_from_array(array1, span)
For counter = 0 To UBound(array1) - span
Result = Result & read_one_ngram_from_array(array1, counter, span) & Chr(13) & Chr(10)
Next
read_all_ngrams_from_array = Result
End Function
附件
Last edited:
李亮1975重庆
语料库快乐军政委
英语ConcGram生成器vbs.zip(ConcGram就是“语块”啦,就是“有一个或多个搜索词的语块”,而N-gram是“不含搜索词的语块”)
高速免费且开放源代码的文本小工具,双击即可运行的vbs脚本小程序。
你可以从“新浪爱问”下载“英语N-gram生成器vbs.zip“,链接是
http://ishare.iask.sina.com.cn/f/24766658.html
你可以从“新浪爱问”下载“英语ConcGram生成器vbs.zip“,链接是
http://ishare.iask.sina.com.cn/f/24767255.html
ConcGram是N-gram的高级形式,因为N-gram就是“无搜索词的多个连续单词的串串”,而ConcGram是“有一个或多个搜索词且不在乎这些搜索词的先后顺序且必须至少含有所有这些搜索词的多个连续单词的串串”。
根据权威文献,ConcGram生成与搜索的软件能帮助语言研究者在搜索“a lot of people”的时候,顺便也能发现“a lot of local people”这样的习语或习惯表达,因为ConcGram是指定进行某个数量的单词所组成的连续的单词串进行搜索,所以,当你去搜索5个词组成的且含 有"a lot of people"这些搜索词的时候,你就能发现“a lot of local people”与“a lot of angry people”与“a lot of silent people”这样的实例,这相当于“模糊查询”哟。
“ConcGram”这个名称也是一款商业版语料库工具的名称,2009年面世,完整名称是“ConcGram 1.0”,售价为91.69美元,销售网址是:
http://www.overstock.com/Books-Movies-Music-Games/Concgram-1.0-CD-ROM/3873739/product.html
亚马逊上的打折价是45英镑,网址是:
http://www.amazon.co.uk/ConcGram-1-0-phraseological-Linguistics-Software/dp/9027240272
亚马逊上的英语介绍是……
ConcGram 1.0 is a corpus linguistics software package which is specifically designed to find all the co-occurrences of words in a text or corpus irrespective of variation. The software finds the co-occurrences fully automatically, in other words, the user inputs no prior search commands. These co-occurrences are termed ‘concgrams’ and include instances of both constituency variation (increase in expenditure, increase in the share of public expenditure)and positional variation (expenditure would inevitably increase). ConcGram 1.0 is therefore uniquely suited to uncovering the full phraseological profile of a text or corpus. In addition to this principal function, ConcGram 1.0 allows the user to nominate concgram searches, and it also has the more traditional functions associated with corpus linguistics software.
The software comes with a detailed online manual in a PDF file, which explains all of the functions and includes a user-friendly tutorial. In addition, the manual includes a discussion of the theoretical issues underpinning the development of the software and the implications of concgramming for the study of phraseology (Why Concgram? by Martin Warren).
The software has a wide range of applications in the fields of Corpus Linguistics, Critical Discourse Analysis, Discourse Analysis, Lexicology, Lexicography, Pragmatics and Semantics.
其PDF的英文手册(94页呢,本帖的附件也提供了)的下载网址是:
http://www.benjamins.com/jbp/series/CLS/1/manual.pdf
百度文库中有精彩的在线阅读的学术文章一篇“From n-gram to skipgram to concgram ”,网址:
http://wenku.baidu.com/view/149a2c7831b765ce05081489.html
“ConcGram 1.0”的开发者是Chris Greaves教授,2010年年初他到华南师范大学与何安平教授的团队进行了学术交流,新闻链接是:
http://sfs.scnu.edu.cn/corpus4u/show.aspx?id=396
本帖所供的vbs版的“ConcGram”在运行时,需要手工输入N-gram的最少单词量与最多单词量(“可以叫做N-gram span”吧)。
灵机一动,操作者不难想到,其实我们可以把本脚本当作一个“KWIC”的工具,假设你输入的span是10,关键词是“good”,就能生成出含有"good"且左右总共10个词的“连续的词串”了,当然如果“good”所在的某个自然段恰好不足10个词,那就无法被检索到了。
本脚本是对同一文件夹(不含子文件夹)的所有.txt文件(必须是ANSI编码哟,否则用本贴子提供的TXT全能转码工具进行转码)进行基于N-gram的ConcGram的生成与对应*.txt文件同名称却不同文件扩展名的*.log,例如“a.txt”的所有ConcGram就生成在“a.log”这个文件了。本工具适合词汇搭配研究与语块提取的语料库的初步需求,并没有进行排序或频率计算或冗余剔除。如果你需要进一步处理,可以导入Microsoft Excel进行排序就可以按照字母顺序来观察了,或者进行“<高级筛选>的<选择不重复的记录>”的操作,就得到“不重复的有序化的语块列表”了。
没有采用复杂的分词机制,仅仅采用空格作为单词之间的切分标准,因此标点符号依然附着在某些单词的“身前身后”而形成一个“单词”。但是,自动以每个自然段作为N-gram的“生成边界”,而没有跨段生成N-gram(即,把某段的最后一个词跟下一段的第一个词视为一个连续的语块)。
对着本脚本点右键,选择“编辑”或“打开方式”为“记事本”,就可以阅读源代码。
经 VirusTotal的42款杀毒引擎检测,只有1款杀毒软件报毒(嘻嘻,当代杀毒软件的智力呀)。这款聪明的杀毒软件的“姓名”与“报告”如下:
Comodo TrojWare.JS.Agent.nge 20120602
现在,假设我们有1.txt进行N-gram或“语块”的生成,而1.txt的内容如下:
Corpus linguistics is a good tool of research.
It can be "driven" and "based".
而运行本脚本,获取2个词到4个词之间的含有“good tool”这两个词的“语块”而生成的1.log则内容如下:
good tool
a good tool
good tool of
is a good tool
a good tool of
good tool of research.
再例如,我们生成5个词到7个词之间的含有“good”这个词的“语块”而生成的1.log则内容如下:
Corpus linguistics is a good
linguistics is a good tool
is a good tool of
a good tool of research.
Corpus linguistics is a good tool
linguistics is a good tool of
is a good tool of research.
Corpus linguistics is a good tool of
linguistics is a good tool of research.
对上面的观察,能加深对语块的认识。
脚本的完整源代码如下……
Set fso1 = CreateObject("scripting.filesystemobject")
tip = "输入2,4表示2到4的N-gram" & Chr(13) & "输入3表示3个词的N-gram" & Chr(13) & "txt文件必须为ANSI文字编码,否则无法正常生成N-gram"
request = Trim(InputBox(tip, "用逗号表达的ngram范围 【李亮研发】", "2,4")) & ","
request = replace(request, " ", "")
If request = "," Then
MsgBox "您取消了程序"
bye = "yes"
End If
request = Split(request, ",")
If UBound(request) >= 1 And bye <> "yes" Then min = Abs(CInt(request(0))) Else min = 0
If UBound(request) >= 2 And bye <> "yes" Then max = Abs(CInt(request(1))) Else max = 0
If min = 0 Then
bye = "yes"
End If
If max < min Then max = min
keywords = Trim(InputBox("输入一个或多个关键词,用空格隔开", "关键词输入", " "))
keywords = replace(keywords, " ", " ")
If bye <> "yes" Then
For Each file1 In fso1.GetFolder(".").Files
If Right(file1.Name, 4) = ".txt" Then
Set old_file = fso1.OpenTextFile(Left(file1.Name, Len(file1.Name) - 4) & ".txt", 1, -2)
Set new_file = fso1.CreateTextFile(Left(file1.Name, Len(file1.Name) - 4) & ".log", True, False)
Do
the_line = Trim(old_file.ReadLine) & " "
the_array = Split(the_line, " ")
If UBound(the_array) >= min Then
For span = CInt(min) To CInt(max)
ngrams = ngrams & read_all_ngrams_from_array(the_array, span, keywords)
Next
End If
Loop Until old_file.AtEndOfStream
new_file.Write(ngrams)
ngrams = ""
old_file.Close
new_file.Close
Set old_file = Nothing
Set new_file = Nothing
End If
Next
MsgBox "本文件夹(不包括子文件夹)处理完毕!所有的.txt文件都生成了对应的.log文件了" & chr(13) & "李亮制作 2012年5月 广东外语外贸大学 词典学研究中心", vbinformation, "英语ConcGram生成器.vbs"
End If
Function read_one_ngram_from_array(array1, start, span, keywords)
result=" "
For counter = start To start + span - 1
Result = Result & array1(counter) & " "
Next
if is_concgram(result, keywords)="false" then result=""
read_one_ngram_from_array = Result
End Function
Function read_all_ngrams_from_array(array1, span, keywords)
For counter = 0 To UBound(array1) - span
tmp = read_one_ngram_from_array(array1, counter, span, keywords)
if tmp <> "" then Result = Result & tmp & Chr(13) & Chr(10)
Next
read_all_ngrams_from_array = Result
End Function
Function is_concgram(string_tmp, keywords)
Result = "true"
string_tmp = Trim(string_tmp)
If string_tmp = "" Then Result = "false"
keywords = Replace(keywords, " ", " ")
keywords = Trim(keywords) & " "
keywords_array = Split(keywords, " ")
word_number = UBound(keywords_array)
For counter = 0 To word_number - 1
If InStr(1, " " & string_tmp & " ", keywords_array(counter)) = 0 Then Result = "false"
Next
is_concgram = Result
End Function
高速免费且开放源代码的文本小工具,双击即可运行的vbs脚本小程序。
你可以从“新浪爱问”下载“英语N-gram生成器vbs.zip“,链接是
http://ishare.iask.sina.com.cn/f/24766658.html
你可以从“新浪爱问”下载“英语ConcGram生成器vbs.zip“,链接是
http://ishare.iask.sina.com.cn/f/24767255.html
ConcGram是N-gram的高级形式,因为N-gram就是“无搜索词的多个连续单词的串串”,而ConcGram是“有一个或多个搜索词且不在乎这些搜索词的先后顺序且必须至少含有所有这些搜索词的多个连续单词的串串”。
根据权威文献,ConcGram生成与搜索的软件能帮助语言研究者在搜索“a lot of people”的时候,顺便也能发现“a lot of local people”这样的习语或习惯表达,因为ConcGram是指定进行某个数量的单词所组成的连续的单词串进行搜索,所以,当你去搜索5个词组成的且含 有"a lot of people"这些搜索词的时候,你就能发现“a lot of local people”与“a lot of angry people”与“a lot of silent people”这样的实例,这相当于“模糊查询”哟。
“ConcGram”这个名称也是一款商业版语料库工具的名称,2009年面世,完整名称是“ConcGram 1.0”,售价为91.69美元,销售网址是:
http://www.overstock.com/Books-Movies-Music-Games/Concgram-1.0-CD-ROM/3873739/product.html
亚马逊上的打折价是45英镑,网址是:
http://www.amazon.co.uk/ConcGram-1-0-phraseological-Linguistics-Software/dp/9027240272
亚马逊上的英语介绍是……
ConcGram 1.0 is a corpus linguistics software package which is specifically designed to find all the co-occurrences of words in a text or corpus irrespective of variation. The software finds the co-occurrences fully automatically, in other words, the user inputs no prior search commands. These co-occurrences are termed ‘concgrams’ and include instances of both constituency variation (increase in expenditure, increase in the share of public expenditure)and positional variation (expenditure would inevitably increase). ConcGram 1.0 is therefore uniquely suited to uncovering the full phraseological profile of a text or corpus. In addition to this principal function, ConcGram 1.0 allows the user to nominate concgram searches, and it also has the more traditional functions associated with corpus linguistics software.
The software comes with a detailed online manual in a PDF file, which explains all of the functions and includes a user-friendly tutorial. In addition, the manual includes a discussion of the theoretical issues underpinning the development of the software and the implications of concgramming for the study of phraseology (Why Concgram? by Martin Warren).
The software has a wide range of applications in the fields of Corpus Linguistics, Critical Discourse Analysis, Discourse Analysis, Lexicology, Lexicography, Pragmatics and Semantics.
其PDF的英文手册(94页呢,本帖的附件也提供了)的下载网址是:
http://www.benjamins.com/jbp/series/CLS/1/manual.pdf
百度文库中有精彩的在线阅读的学术文章一篇“From n-gram to skipgram to concgram ”,网址:
http://wenku.baidu.com/view/149a2c7831b765ce05081489.html
“ConcGram 1.0”的开发者是Chris Greaves教授,2010年年初他到华南师范大学与何安平教授的团队进行了学术交流,新闻链接是:
http://sfs.scnu.edu.cn/corpus4u/show.aspx?id=396
本帖所供的vbs版的“ConcGram”在运行时,需要手工输入N-gram的最少单词量与最多单词量(“可以叫做N-gram span”吧)。
灵机一动,操作者不难想到,其实我们可以把本脚本当作一个“KWIC”的工具,假设你输入的span是10,关键词是“good”,就能生成出含有"good"且左右总共10个词的“连续的词串”了,当然如果“good”所在的某个自然段恰好不足10个词,那就无法被检索到了。
本脚本是对同一文件夹(不含子文件夹)的所有.txt文件(必须是ANSI编码哟,否则用本贴子提供的TXT全能转码工具进行转码)进行基于N-gram的ConcGram的生成与对应*.txt文件同名称却不同文件扩展名的*.log,例如“a.txt”的所有ConcGram就生成在“a.log”这个文件了。本工具适合词汇搭配研究与语块提取的语料库的初步需求,并没有进行排序或频率计算或冗余剔除。如果你需要进一步处理,可以导入Microsoft Excel进行排序就可以按照字母顺序来观察了,或者进行“<高级筛选>的<选择不重复的记录>”的操作,就得到“不重复的有序化的语块列表”了。
没有采用复杂的分词机制,仅仅采用空格作为单词之间的切分标准,因此标点符号依然附着在某些单词的“身前身后”而形成一个“单词”。但是,自动以每个自然段作为N-gram的“生成边界”,而没有跨段生成N-gram(即,把某段的最后一个词跟下一段的第一个词视为一个连续的语块)。
对着本脚本点右键,选择“编辑”或“打开方式”为“记事本”,就可以阅读源代码。
经 VirusTotal的42款杀毒引擎检测,只有1款杀毒软件报毒(嘻嘻,当代杀毒软件的智力呀)。这款聪明的杀毒软件的“姓名”与“报告”如下:
Comodo TrojWare.JS.Agent.nge 20120602
现在,假设我们有1.txt进行N-gram或“语块”的生成,而1.txt的内容如下:
Corpus linguistics is a good tool of research.
It can be "driven" and "based".
而运行本脚本,获取2个词到4个词之间的含有“good tool”这两个词的“语块”而生成的1.log则内容如下:
good tool
a good tool
good tool of
is a good tool
a good tool of
good tool of research.
再例如,我们生成5个词到7个词之间的含有“good”这个词的“语块”而生成的1.log则内容如下:
Corpus linguistics is a good
linguistics is a good tool
is a good tool of
a good tool of research.
Corpus linguistics is a good tool
linguistics is a good tool of
is a good tool of research.
Corpus linguistics is a good tool of
linguistics is a good tool of research.
对上面的观察,能加深对语块的认识。
脚本的完整源代码如下……
Set fso1 = CreateObject("scripting.filesystemobject")
tip = "输入2,4表示2到4的N-gram" & Chr(13) & "输入3表示3个词的N-gram" & Chr(13) & "txt文件必须为ANSI文字编码,否则无法正常生成N-gram"
request = Trim(InputBox(tip, "用逗号表达的ngram范围 【李亮研发】", "2,4")) & ","
request = replace(request, " ", "")
If request = "," Then
MsgBox "您取消了程序"
bye = "yes"
End If
request = Split(request, ",")
If UBound(request) >= 1 And bye <> "yes" Then min = Abs(CInt(request(0))) Else min = 0
If UBound(request) >= 2 And bye <> "yes" Then max = Abs(CInt(request(1))) Else max = 0
If min = 0 Then
bye = "yes"
End If
If max < min Then max = min
keywords = Trim(InputBox("输入一个或多个关键词,用空格隔开", "关键词输入", " "))
keywords = replace(keywords, " ", " ")
If bye <> "yes" Then
For Each file1 In fso1.GetFolder(".").Files
If Right(file1.Name, 4) = ".txt" Then
Set old_file = fso1.OpenTextFile(Left(file1.Name, Len(file1.Name) - 4) & ".txt", 1, -2)
Set new_file = fso1.CreateTextFile(Left(file1.Name, Len(file1.Name) - 4) & ".log", True, False)
Do
the_line = Trim(old_file.ReadLine) & " "
the_array = Split(the_line, " ")
If UBound(the_array) >= min Then
For span = CInt(min) To CInt(max)
ngrams = ngrams & read_all_ngrams_from_array(the_array, span, keywords)
Next
End If
Loop Until old_file.AtEndOfStream
new_file.Write(ngrams)
ngrams = ""
old_file.Close
new_file.Close
Set old_file = Nothing
Set new_file = Nothing
End If
Next
MsgBox "本文件夹(不包括子文件夹)处理完毕!所有的.txt文件都生成了对应的.log文件了" & chr(13) & "李亮制作 2012年5月 广东外语外贸大学 词典学研究中心", vbinformation, "英语ConcGram生成器.vbs"
End If
Function read_one_ngram_from_array(array1, start, span, keywords)
result=" "
For counter = start To start + span - 1
Result = Result & array1(counter) & " "
Next
if is_concgram(result, keywords)="false" then result=""
read_one_ngram_from_array = Result
End Function
Function read_all_ngrams_from_array(array1, span, keywords)
For counter = 0 To UBound(array1) - span
tmp = read_one_ngram_from_array(array1, counter, span, keywords)
if tmp <> "" then Result = Result & tmp & Chr(13) & Chr(10)
Next
read_all_ngrams_from_array = Result
End Function
Function is_concgram(string_tmp, keywords)
Result = "true"
string_tmp = Trim(string_tmp)
If string_tmp = "" Then Result = "false"
keywords = Replace(keywords, " ", " ")
keywords = Trim(keywords) & " "
keywords_array = Split(keywords, " ")
word_number = UBound(keywords_array)
For counter = 0 To word_number - 1
If InStr(1, " " & string_tmp & " ", keywords_array(counter)) = 0 Then Result = "false"
Next
is_concgram = Result
End Function
附件
Last edited: